4. SW/HW/DB 신기술 - 74. DB 신기술
74. DB 신기술
1. SAN
2. SDS
3. 데이터마이닝
4. HADOOP
5. 맵리듀스
RAID (Redundant Array of Inexpensive Disk)
불필요한 배열의 비싸지 않은 디스크
하드디스크를 연결하는 기법
요즘 영상업체들은 NAS(Network Area Storage), DAS(네트워크에 연결되는 게 아닌 컴퓨터에 연결을 하는데, NAS와 비슷하게 RAID기능을 제공한다.) 이런 장치들을 쓴다.
RAID 예)
10TB짜리 영상이 있는데, 10TB하드를 사면 비싸니깐 2TB 5개를 구매해서 애네를 DAS에 꽂는다. 그리고 얘네들을
RAID로 묶어버리면 10TB 디스크 하나로 쓸 수 있다.
NAS도 마찬가지이다. 즉 NAS나 DAS는 저장장치가 되는 것이다.
여러 대의 하드디스크가 있을 때 동일한 데이터를 다른 위치에 중복해서 저장하는 방법으로 디스크의 고장에 대비하여 데이터의 안정성을 높이는 기술이다.
신뢰성이냐? 아니면 확장이냐? 두 가지 중 선택한다.
RAID의 종류는 0부터 시작한다.
| RAID의 종류 | |
| RAID 0 스트라이프(Stripe)  |
● 2개 이상의 하드 디스크를 병렬로 연결해서 하나의 디스크처럼 사용하는 방식이다. 디스크 드라이브가 동시에 액세스가 일어나서 디스크의 개수가 늘어날수록 성능이 향상되며 연결된 디스크 중 가장 작은 용량 기준으로 디스크가 묶인다. 예 ) 2TB와 3TB를 연결하면 2TB로 인식한다. ● 스트라이프는 줄무늬이다. 그런것처럼 하드디스크를 순서대로 저장한다. ● 똑같은 용량이 가장 좋다 예 ) A,B디스크가 있고, 자료를 넣을 때 A디스크에 A1넣고 B디스크에 A2넣고, A디스크에 A3넣고, B디스크에 A4 넣고, 이런식으로 분리해서 넣는다. 즉, 하나의 디스크처럼 여기저기 나눠서 넣는것이다. 대신 A1을 찾을때는 A디스크만 돌아가면 되고, A2 찾을때는 B디스크만 돌아가면 된다. 그래서 성능이 높아진다. 만약 애네 디스크를 늘리게 되면 더 빨리 읽고 쓰기가 가능하다. 그래서 어떤 성능에 관련된 부분은 RAID 0 이다. |
| RAID 1 미러(Mirror) 지원으로 1개 디스크 고장에도 데이터 복구 가능 |
● 동일한 용량의 2개 이상의 하드디스크를 병렬로 연결하여, 동일한 데이터를 동시에 각 디스크에 저장되어 신뢰성이 높다. ● 똑같은 용량이 가장 좋다 예 ) A,B디스크가 있고, 자료를 넣을 때 똑같이 들어간다. A디스크에 A1이 들어가면 B디스크도 A1이 들어간다. 이런식으로 똑같이 미러링 되는 것을 RAID 1이라고 한다. |
RAID 2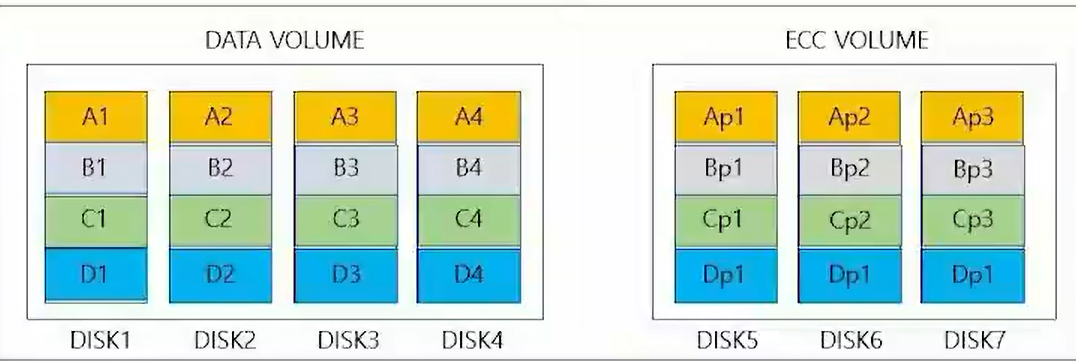 |
● RAID0과 1은 오류를 체크할 수 있는 기능이 없다. 그래서 불안하기 때문에 비트 단위로 분산 저장하고 여러 개의 해밍코드 검사 디스크를 사용한다. ● 디스크 미러링(DIsk Mirroring) 방식으로 높은 신뢰도를 갖는다. |
| RAID 3 Parity 체크용 디스크를 1개 별도로 사용 |
디스크가 2개가 있으면 이 2개외의 별도의 하드디스크를 둔다. 즉, 데이터를 다수의 디스크에 스트라이핑하여 저장하며, 하나의 드라이브에 패리티를 저장한다. 패리티 드라이브를 사용한다. |
| RAID 4 Block 단위로 Stripe 한다. |
각 디스크에 데이터를 블록 단위로 분산 저장하고 하나의 패리티 검사 디스크를 사용한다 (블록 인터리브된 패리티(Block-interleaved Striping with Parity)). |
| RAID 5 Parity 정보를 매번 다른 디스크에 저장하여 데이터 복구가 가능 |
별도의 패리티 디스크 대신 모든 디스크에 패리티 정보를 나누어 기록하는 방식으로 3개 이상의 디스크를 요구하며 쓰기 작업이 많지 않은 주로 읽어들이는 다중 시스템에 적합하다. 예 ) A디스크에 해당하는 자료의 패리티는 B디스크에 넣고 B디스크에 해당하는 패리티는 3디스크에 넣고 3디스크에 해당하는 패리티는 A디스크에 넣는다. |
| RAID 1+0 RAID 1 구성에서 쓰기 성능을 높일 수 있음 |
- RAID 1 방식으로 데이터 미러링하고, 이를 다시 RAID 0 방식으로 스트라이핑하는 방식이다. - 성능을 높일 때 쓴다. |
| RAID 0+1 | RAID 0 방식으로 스트라이핑 한 디스크 2개를 서로 RAID 1 방식으로 미러링한다. |
| JBDD (Just a Bunch of Disks) 여러 디스크를 연결하여 하나의 큰 용량의 디스크로 인식(Spanning) |
두 개 이상의 하드 드라이브가 하나의 큰 하드 드라이브로 OS X에서 Mac에 나타날 수 있도록 한다. |
웨어러블 컴퓨팅 (Wearable Computing)
컴퓨터를 옷이나 안경처럼 착용할 수 있게 해주는 기술이다.
소형화, 경량화를 비롯해 음성과 동작 이식 등 다양한 기술이 적용되어 장소에 구애받지 않고 컴퓨터를 활용할 수 있다.
멤리스터 (Memristor)
메모리와 레지스터의 합성어이다.
전류의 방향과 크기 등 기존의 상태를 모두 기억하는 소자이다.
# 소자
장치, 전자 회로 따위의 구성 요소가 되는 낱낱의 부품으로, 독립된 고유의 기능을 가지고 있는 것. 진공관ㆍ트랜지스터와 같은 능동 소자, 저항 코일ㆍ콘덴서와 같은 수동 소자로 나눈다.
레지스터, 커패시터, 인덕터에 이어 네 번째 전자 회로 구성 요소이다.
차세대 기억 소자, 회로 등에 응용될 수 있다. 에너지 소모와 부팅 시간을 획기적으로 줄일 수 있다.
직접 연결 저장 장치 (DAS : Direct - Attached Storage)
하드디스크와 같은 데이터 저장 장치를 호스트 버스 어댑터에 직접 연결하는 방식이다.
- 저장 장치와 호스트 기기 사이에 네트워크 디바이스가 있지 말아야 한다.
- 네트워크와 연결되는 것이 아니다. 네트워크와 연결된다면 그것은 NAS가 된다.
1. SAN (Storage Area Network) ☆
LAN처럼 근거리 통신망, 광역 통신망처럼 Storage를 영역으로 묶는 것이다.
네트워크상에 광 채널 스위치의 이점인 고속 전송과 장거리 연결 및 멀티 프로토콜 기능을 활용하여
각기 다른 운영체제를 가진 여러 기종이 네트워크상에서 동일 저장 장치의 데이터를 공유하게 함으로써, 여러 개의 저장 장치나 백업 장비를 단일화시킨 시스템이다.
NAS (Network Attached Storage)
컴퓨터에 직접 연결하지 않고 네트워크를 통해 데이터를 주고받는 저장 장치이다.
구조적으로는 스토리지 서버를 단순화, 소형화한 것이다.
2. SDS : Software Defined Storage ☆
가상화를 적용하여 필요한 공간만큼 나눠 사용할 수 있도록 하며 서버 가상화와 유사하다.
컴퓨팅 소프트웨어로 규정하는 데이터 체계이며, 일정 조직 내 여러 스토리지를 하나처럼 관리하고 운용하는 컴퓨터 이용 환경으로 스토리지 자원을 효율적으로 나누어 쓰는 방법이다.
예) 만약 월 20만 원을 내고 서버를 구축해 서버 호스팅을 받는다면
요즘 서버는 어마어마하게 성능이 좋다. 그래서 가용성면만 보면 10%도 다 사용을 못한다.
그러면 서버회사에서 "내가 이거 3만 원에 해줄게 이거 우리 10개로 나눠가지고 서비스하면 안 될까?"라고 하는 게 가상화시스템이고, 거기에서 마찬가지로 저장장치를 가상화해서 쪼개서 나눠서 사용할 수 있도록 하는 것이 SDS이다.
- 호스팅 같은 거 받으려고 서비스 가보면 가상화된 시스템을 따로 저렴하게 판매하고 있다.
- 윈도 서버나, 리눅스 서버에 기본적으로 가상화해서 나눠서 사용할 수 있는 기능도 담겨있다.
데이터웨어하우스 (Data Warehouse)
기간 업무 시스템에서 추출되어 새로이 생성된 데이터베이스이다.
의사결정 지원시스템을 지원하는 주제적, 통합적, 시간적 데이터의 집합체이다.
통합된 데이터에 대한 OLAP(On-Line Analytical Processing) 연산을 효율적으로 지원할 수 있다.
이런 데이터들을 보관하고 분석해서 어떤 의미 있는 것을 찾아내는 것이다
빅데이터 (Big Data)
많은 양의 정형 또는 비정형 데이터들로부터 가치를 추출하고 결과를 분석하는 기술이다.
구글 및 페이스북, 아마존의 경우 이용자의 성향과 검색패턴, 구매패턴을 분석해 맞춤형 광고를 제공하는 등 빅 데이터의 활용을 증대시키고 있다.
빅테이터의 특성
| 빅데이터의 특성 |
| Volume (규모) |
| Velocity (속도) |
| Variety (다양성) |
3. 데이터 마이닝 (Data Mining) ☆
Mining
채굴, 금광을 채굴하는 것이다.
이렇게 많은 데이터에서 내가 의미 있는 것을 찾아내는 것을 데이터 마이닝이라고 한다.
대량의 데이터를 분석하여 데이터 속에 있는 변수 사이의 상호관계를 규명하여 일정한 패턴을 찾아내는 기법이다.
데이터웨어하우징에서 수집되고 분석된 자료를 사용자에게 제공하기 위해 분류 및 가공되는 요소 기술이다.
디지털 아카이빙 (Digital Archiving)
디지털 정보 자원을 장기적으로 보존하기 위한 작업이다.
아날로그 콘텐츠는 디지털로 변환해 압축해서 저장하고, 디지털 콘텐츠도 체계적으로 분류하고 메타 데이터를 만들어 DB 화하는 작업이다.
4. 하둡 (Hadoop) ☆
오픈소스를 기반으로 한 분산 컴퓨팅 플랫폼으로 일반 PC급 컴퓨터들로 가상화된 대형 스토리지를 형성하고
그 안에 보관된 거대한 데이터 세트를 병렬로 처리할 수 있도록 빅데이터 분산 처리를 돕는 자바 소프트웨어 오픈소스 프레임워크이다.
다양한 소스를 통해 생성된 빅데이터를 효율적으로 저장하고 처리한다.
하둡의 필수 핵심 구성 요소는 맵리듀스와 하둡 분산파일 시스템이다.
Sqoop
하둡과 관계형 데이터베이스 간에 데이터를 전송할 수 있도록 설계된 도구이다.
5. 맵리듀스 (Map Reduce) ☆
HADDOP의 핵심 구성 요소로서 대용량 데이터를 분산 처리하기 위한 목적으로 개발된 프로그래밍 모델이다.
- Google에 의해 고안된 기술로써 대표적인 대용량 데이터 처리를 위한 병렬 처리 기법을 제공한다.
- 임의의 순서로 정렬된 데이터를 분산 처리하고 이를 다시 합치는 과정을 거친다.

문제 풀이
1. 다음 보기에서 설명하는 용어는?
- 대용량 데이터를 분산 처리하기 위한 목적으로 개발된 프로그래밍 모델이다.
- Google에 의해 고안된 기술로써 대표적인 대용량 데이터 처리를 위한 병렬 처리 기법을 제공한다.
- 임의의 순서로 정렬된 데이터를 분산 처리하고 이를 다시 합치는 과정을 거친다.
맵리듀스
2. 빅데이터 분석 기술 중 대량의 데이터는 분석하여 데이터 속에 있는 변수 사이의 상호관계를 규명하여 일정한 패턴을 찾아내는 기법은?
① Data Mining
② Wm-Bus
③ Digital Twin
④ Zigbee
1번
3. 다음이 설명하는 용어로 옭은 것은?
- 오픈소스를 기반으로 한 분산 컴퓨팅 플랫폼이다.
- 일반 PC급 컴퓨터들로 가상화된 대형 스토리지를 형성한다.
- 다양한 소스를 통해 생성된 빅데이터를 효율적으로 저장하고 처리한다.
① 하둡(Hadoop)
② 비컨(Beacon)
③ 포스퀘어(Foursquare)
④ 멤리스터(Memristor)
1번
4. RAID-5는 RAID-4의 어떤 문제점을 보완하기 위하여 개발되었는가?
① 병렬 액세스의 불가능
② 긴 쓰기 동작 시간
③ 패리티 디스크의 액세스 집중
④ 많은 수의 검사 디스크 사용
3번