
- 분류 전체보기 (561)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- 레지스터
- 장치에 할당할 수 없는 NET ID Broadcast주소
- 미래 사회의 단위
- 컴퓨터
- 운영체제의 기능 1. 자원 관리 기능 2. 시스템 보호 3. 네트워크(통신 기능)
- 공부정리
- 절차적 사고
- 국립과천과학관
- 출력
- 운영체제의 미래
- 소프트웨어 시대
- 뿌..
- 반복 구조 찾기
- 프로그래밍
- 해결 방안
- 소프트웨어
- 딥러닝
- 앨런 튜링
- 처리
- 순서도
- gensim 3.7.3 설치 오류
- 운영체제 서비스
- 겁나 많아
- 말 인용
- 기계어
- 운영체제의 발달 과정
- 선택
- 운영체제 목적
- 패킷트레이서 이용
- 절차적 사고의 장점
- Today
- Total
hye-_
다변량 데이터 탐색 본문
변량(Variate)이란 변수가 가지는 특징, 성질을 숫자 또는 문자로 나타낸 값을 의미한다.
변수(variable)가 있다면,
그 변수는 어떤 대상의 특징을 담고 있고,
그 특징이 실제 데이터 값으로 표현될 때
그 “값” 하나하나를 변량(variate)이라고 부른다는 뜻이다.
즉,
- 변수 = 키, 몸무게, 성별, 나이 같은 “개념”
- 변량 = 170cm, 60kg, 남자, 25세 같은 “실제 값”
왜 변량이라고 따로 부르는데?
왜냐하면 통계학에서는
“개념으로서의 변수(variable)”와
“그 변수에 들어있는 실제 관측값(observation)”을
구분해야 하기 때문이다.
왜 구분해야 하냐면,
통계 분석은 변수 자체를 계산하는 것이 아니라
그 변수에 들어있는 변량들의 분포, 평균, 분산 등을 계산하기 때문이다.
즉,
우리는 키라는 개념을 계산하는 게 아니라
170, 165, 180 같은 변량들의 집합을 계산한다.
- Variable (변수)
변할 수 있는 속성, 특성, 개념 - Variate (변량)
그 변수에 대해 관측된 실제 값
수식으로 보면
변수 ( X ) 가 있다고 하자.
학생 5명의 키를 측정했다면,
X = {170, 165, 180, 175, 160}
여기서
- X = 변수 (키)
- 170, 165, 180, 175, 160 = 각각의 변량
예시
| 학생 | 키(X) |
| A | 170 |
| B | 165 |
| C | 180 |
여기서 X는 변수,
170, 165, 180은 변량이다.
통계학에서 다중(Multiple)은 독립변수가 여러 개라는 뜻이고, 단변량(일변량)은 종속변수가 한 개이며, 다변량은 단변량(일반량)에 반대되는 것으로 종속변수가 여러 개(두 개 이상)라는 뜻으로 정의한다.
왜냐하면 여기서 “다중”과 “다변량”을 헷갈리기 때문이다.
먼저 독립변수와 종속변수부터 정리
- 독립변수 (Independent Variable, IV)
설명하는 변수 - 종속변수 (Dependent Variable, DV)
설명받는 변수
예를 들어,
공부시간 → 시험점수
- 공부시간 = 독립변수
- 시험점수 = 종속변수
다중(Multiple)의 의미
다중은 독립변수가 여러 개라는 뜻
왜 독립변수 개수로 정의하느냐면,
회귀분석(regression)에서는
모형을 설명할 때 “설명변수 개수”가 중요하기 때문이다.
예를 들어,

- Y = 종속변수 1개
- X1, X2 = 독립변수 2개
이걸 다중 회귀(Multiple Regression)라고 부른다.
왜냐하면 설명하는 변수가 여러 개이기 때문이다.
단변량(Univariate)
종속변수가 한 개
왜 종속변수 개수로 정의하느냐면,
분석의 목적은 결국 예측하고자 하는 대상이기 때문이다.

여기서 Y가 하나이므로 단변량이다.
다변량(Multivariate)
종속변수가 여러 개
예를 들어,

- Y1 = 수학점수
- Y2 = 영어점수
종속변수가 2개이므로
이건 다변량 분석이다.
왜 통계학에서는 종속변수 개수로 정의하나?
왜냐하면
분석의 목표(target)는 종속변수이기 때문이다.
독립변수는 설명 수단이고,
종속변수는 우리가 알고 싶은 대상이다.
그래서
통계학 이론에서는
종속변수 개수가 분석 유형을 결정한다.
통계학 영역을 제외한 데이터 분석에서는 변수의 개수에 따라, 변수가 한 개면 단변량, 두 개면 이변량(Bivariate), 세 개 이상이면 다변량(Multivariate) 데이터로 주로 표현한다.
여기서 완전히 다른 기준이 나온다.
통계학 이론과
실무 데이터 분석에서
정의 기준이 다르다.
왜 실무에서는 변수 전체 개수로 나누나?
왜냐하면
실무에서는 독립/종속 구분 없이
데이터 구조 자체의 복잡도를 말하는 경우가 많기 때문이다.
예를 들어,
| 키 |
→ 단변량 데이터
| 키 | 몸무게 |
→ 이변량 데이터
| 키 | 몸무게 | 나이 |
→ 다변량 데이터
이건 단순히 컬럼(column) 개수 기준이다.
예시로 비교
통계학 기준
- Y 하나 → 단변량
- Y 두 개 → 다변량
데이터 분석 실무 기준
- 변수 1개 → 단변량
- 변수 2개 → 이변량
- 변수 3개 이상 → 다변량
왜 이런 차이가 생겼을까?
왜냐하면 통계학은
모형 중심(Model-centric) 학문이고
데이터 분석은
데이터 구조(Data-centric) 중심이기 때문이다.
통계학은
“무엇을 예측하는가?”가 중요하고
데이터 분석은
“데이터가 몇 차원인가?”가 중요하다.
차원과 연결해서 보자
변수 개수 = 차원 수다.
- 1개 변수 → 1차원
- 2개 변수 → 2차원 평면
- 3개 변수 → 3차원 공간
- n개 변수 → n차원 공간
즉, 다변량 데이터란
고차원 공간에 존재하는 데이터라는 뜻이다.
2차원 예시 그림
키(X)와 몸무게(Y)가 있을 때:




이건 이변량 데이터다.
왜냐하면 변수 2개 → 2차원 평면이기 때문이다.
3차원 예시 그림
키(X), 몸무게(Y), 나이(Z)




이건 다변량 데이터다.
왜냐하면 변수 3개 → 3차원 공간이기 때문이다.
정리
- 변량 = 변수의 실제 값
- 통계학에서 다중 = 독립변수 여러 개
- 통계학에서 다변량 = 종속변수 여러 개
- 실무 데이터 분석에서 다변량 = 변수 3개 이상
- 변수 개수 = 차원 수
- 다변량 = 고차원 공간 데이터
단변량(일변량) · 이변량 · 다변량 비교표

단변량 (Univariate)
의미
하나의 변수만을 독립적으로 분석한다.
관계가 아니라 “그 변수 자체의 모양”을 본다.
목적
왜 중심값과 산포를 보느냐면
데이터의 전반적 특성을 이해해야 이후 분석이 가능하기 때문이다.
예시
학생 키 데이터:

시각화



이변량 (Bivariate)
의미
두 변수 사이의 관계를 분석한다.
왜 중요한가
왜 두 개를 동시에 보느냐면
현실의 대부분 현상은 관계에서 발생하기 때문이다.
예:
공부시간(X) → 성적(Y)
수식

시각화




다변량 (Multivariate)
의미
세 개 이상의 변수를 동시에 고려한다.
왜 필요한가

행렬 형태

대표 기법
- 다중회귀 (Multiple Regression)
- 주성분분석(PCA)
- 군집분석(Clustering)
- 판별분석(Discriminant Analysis)
시각화 예시




차원 관점에서 다시 보면
| 변수 개수 | 공간 차원 | 의미 |
| 1 | 1차원 | 선 |
| 2 | 2차원 | 평면 |
| 3 | 3차원 | 공간 |
| n | n차원 | 고차원 공간 |
즉,
단변량 → 1차원 세계
이변량 → 2차원 관계
다변량 → 고차원 구조
통계 기반 다변량 탐색 기법에는 변수들 간의 관계 규명(인과관계, 상관관계 등) 하거나 변수들 간의 상관관계를 이용하여 변수를 축소, 또는 개체들을 분류하는데 관련된 분석 기법 등이 있다.
“다변량 탐색”이라는 것이 단순히 변수가 많다는 의미가 아니라,
여러 변수 사이의 구조를 이해하려는 시도라는 뜻이다.
즉, 다변량 탐색은 세 가지 방향으로 나뉜다.
- 변수들 사이 관계를 밝히는 것
- 변수 자체를 줄이는 것
- 개체(사람, 객체)를 분류하는 것
왜 이렇게 세 가지로 나누는가?
왜냐하면 다변량 데이터는 본질적으로 “행렬 구조”이기 때문이다.
데이터는 보통 이렇게 생긴다:

행(row) = 개체
열(column) = 변수
왜 분석 방향이 3가지로 나뉘느냐면
- 열 중심 분석 → 변수 관계
- 열 축소 → 차원 축소
- 행 중심 분석 → 개체 분류
이렇게 분석의 초점이 다르기 때문이다.
1) 변수들 간의 관계
변수들 간의 인과관계, 상관관계 및 평균과 분산 등의 차이를 탐색하는 방법
여기서는 개체가 아니라 “변수와 변수 사이의 관계”를 본다는 뜻이다.
왜 변수 간 관계를 보나?
왜냐하면 현실 세계는 단일 변수로 설명되지 않기 때문이다.
예를 들어,
성적은 공부시간만으로 설명되지 않고
수면시간, 스트레스, 집중력 등과 연결되어 있다.
따라서 우리는

처럼 모델을 세운다.
분석 기법 설명
1-1. 다중회귀분석 (Multiple Regression)
왜 쓰냐면
하나의 종속변수를 여러 독립변수로 설명하기 위해 사용한다.
수식:

여기서

1-2. 로지스틱 회귀
왜 쓰냐면
종속변수가 0/1 같은 범주형일 때 확률을 예측하기 위해 사용한다.

1-3.다변량 분산분석 (MANOVA)
왜 쓰냐면
집단 간 평균 차이를 여러 종속변수 기준으로 동시에 비교하기 위해 사용한다.
1-4.상관관계 분석

왜 쓰냐면
선형 관계 강도를 정량화하기 위해 사용한다.
1-5. 교차분석
범주형 변수들 간 독립성 확인

변수 관계 시각화

2) 데이터의 차원 축소
변수들 간의 상관관계를 분석하여 가지고 있는 의미를 유지하면서(정보 손실 최소화) 변수를 요약하고자 할 때 사용하는 방법
여기서는 변수를 줄인다.
하지만 그냥 버리는 게 아니라,
정보를 압축한다.
왜 차원 축소가 필요한가?
왜냐하면 고차원 데이터에서는
- 계산 복잡도 증가
- 다중공선성 문제
- 시각화 불가능
문제가 발생하기 때문이다.
2-1. PCA (주성분분석)
왜 쓰냐면
분산이 가장 큰 방향을 찾기 위해 사용한다.
수식:

왜 고유값을 보냐면
그 값이 분산 크기를 나타내기 때문이다.
PCA 시각화

2-2. 요인분석 (FA)
왜 쓰냐면
관측변수 뒤에 숨은 잠재요인(latent factor)을 찾기 위해 사용한다.

2-3. 정준상관분석 (CCA)
왜 쓰냐면
두 변수 집합 간의 최대 상관 방향을 찾기 위해 사용한다.
상관분석은:
A랑 B 얼마나 관련?
정준상관은:
A그룹 전체랑 B그룹 전체 얼마나 관련?
3) 케이스 차원 축소 (개체 분류)
변수들이 가지는 값들의(개체들의) 유사성을 이용하여 분류하고자 할 때 사용하는 방법
이번에는 열이 아니라 행을 본다.
즉, 사람과 사람의 유사성을 계산한다.
왜 개체 분류가 필요한가?
왜냐하면 데이터 안에는 자연스러운 그룹이 존재하기 때문이다.
예:
고객 → VIP / 일반 / 이탈 가능
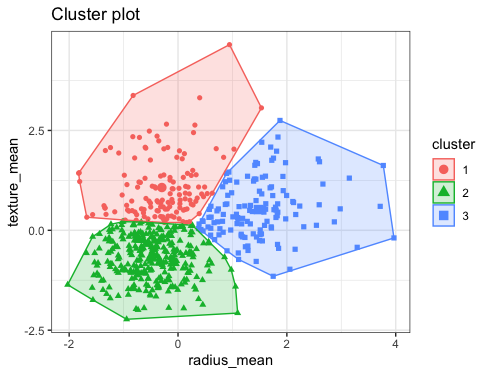
3-1.군집분석
왜 쓰냐면
라벨 없이 유사한 개체끼리 묶기 위해 사용한다.
K-means 수식:

3-2.판별분석
왜 쓰냐면
이미 집단이 있을 때 구분 규칙을 찾기 위해 사용한다.
3-3.다차원척도법 (MDS)
왜 쓰냐면
거리 행렬을 저차원 공간으로 시각화하기 위해 사용한다.
군집 시각화



핵심 구조
| 분석 초점 | 무엇을 줄이는가? | 대상 |
| 변수 관계 | 관계 해석 | 열 중심 |
| 차원 축소 | 변수 수 | 열 압축 |
| 개체 분류 | 행 수 구조 | 행 중심 |
변수들 간의 관계 분석 기법
변수들 간의 인과관계, 상관관계 및 평균과 분산 등의 차이를 탐색하는 방법은 다음과 같다.
“다변량 탐색” 중에서도
특히 변수와 변수 사이의 관계를 밝히는 분석을 말한다는 뜻이다.
여기서 핵심은 세 가지다.
- 인과관계 (Cause → Effect 구조)
- 상관관계 (같이 움직이는 정도)
- 평균·분산 차이 (집단 간 차이)
왜 관계를 탐색해야 하는가?
왜냐하면 데이터 분석의 궁극 목적은
단순한 숫자 요약이 아니라 “구조를 이해하는 것”이기 때문이다.
왜 구조를 알아야 하냐면
예측, 정책 결정, 의사결정은
관계 구조를 기반으로 이루어지기 때문이다.
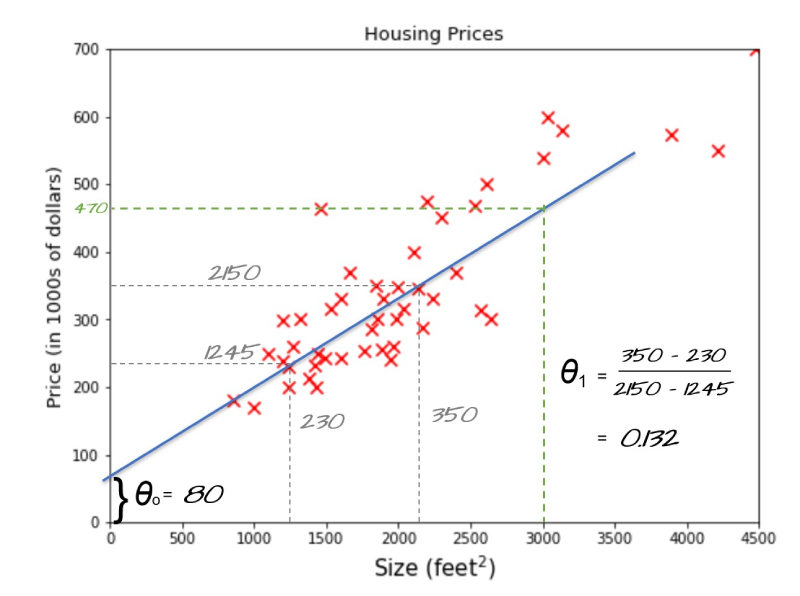
1. 다중회귀분석
연속형 종속변수와 두 개 이상의 연속형 독립변수 간에 관련성이 있다고 가정되는 연구 문제에 적합한 분석 방법
여기서는 종속변수가 연속형이라는 것이 핵심이다.
즉, 결과값이 숫자 범위 전체에서 움직인다.
예: 집값, 매출액, 범죄율
왜 다중이 필요한가?
왜 단순회귀가 아니라 다중회귀냐면
현실 현상은 하나의 원인으로 설명되지 않기 때문이다.
왜 집값이 방 개수만으로 결정되지 않느냐면
교육 수준, 치안, 교통, 재산 가치 등 복합 요인이 작용하기 때문이다.
수식

왜 이 수식이 중요한가 하면
각 beta_i는 다른 변수가 고정된 상태에서
해당 변수의 순수 영향력을 의미하기 때문이다.
사례 연결
범죄율, 방의 수, 재산, 교육수준 → 주택가격 예측
왜 회귀가 적합하냐면
주택가격은 연속형 숫자이기 때문이다.
다중회귀 구조 그림

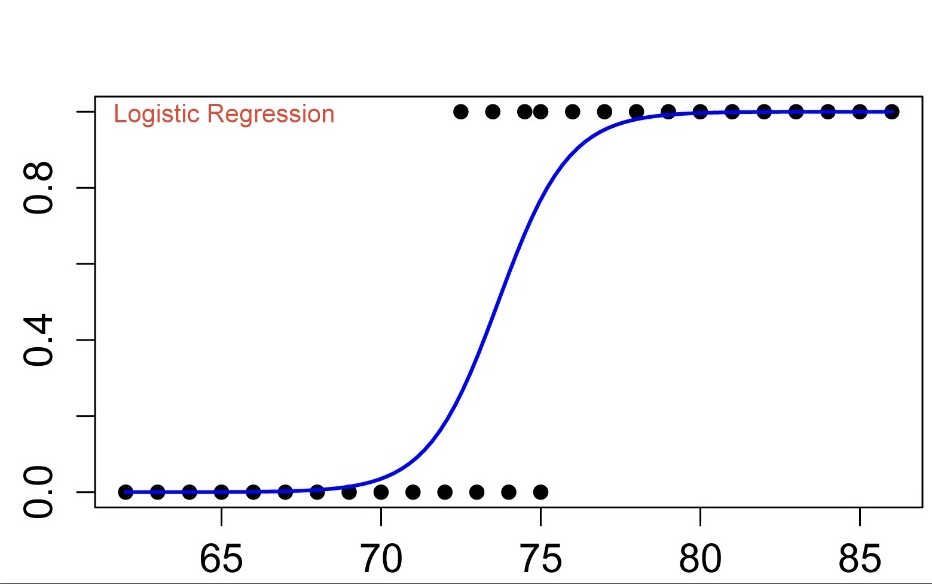
2. 로지스틱 회귀
종속변수가 이진변수이거나 순서형 변수(범주)인 경우 사용되는 회귀분석 방법
여기서는 종속변수가 숫자 범위가 아니라
0/1 같은 범주라는 것이 핵심이다.
왜 일반 회귀를 쓰지 않나?
왜냐하면 선형회귀는 예측값이
(-∞ ~ +∞) 범위를 가지기 때문이다.
왜 그게 문제냐면
확률은 0~1 사이여야 하기 때문이다.
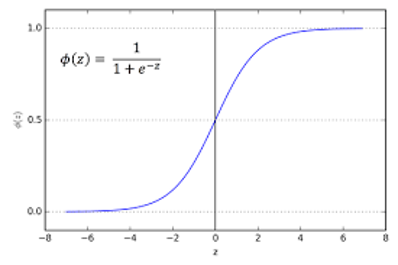
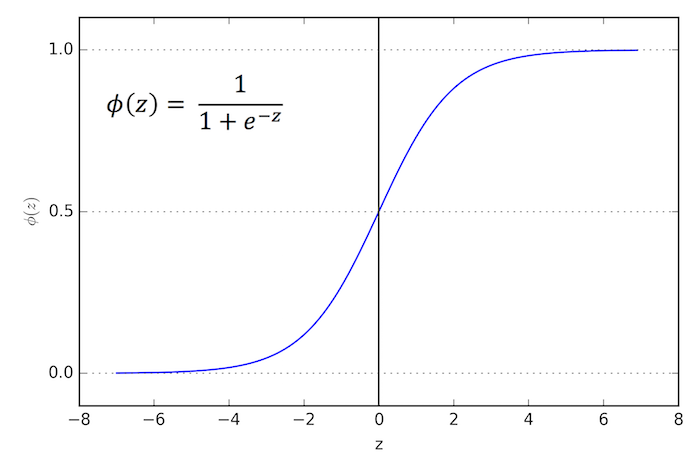
수식

왜 시그모이드 함수가 쓰이냐면
출력을 0과 1 사이로 압축하기 때문이다.
사례 연결
통신사 번호이동 여부 (1/0)
왜 적합하냐면
결과가 두 가지 선택 중 하나이기 때문이다.
로지스틱 함수 시각화
3. 다변량분산분석 (MANOVA)
두 개 이상의 연속형 종속변수와 다수의 범주형 독립변수 간의 관련성을 동시에 알아볼 때 이용
종속변수가 여러 개라는 것이다.
왜 여러 종속변수를 동시에 분석하나?
왜냐하면 여러 결과 변수가 서로 상관되어 있기 때문이다.
왜 따로 분석하면 안 되느냐면
종속변수 간 공분산 구조를 무시하게 되기 때문이다.
기본 개념 수식
분산-공분산 행렬 기반 분석:

여기서
Y는 종속변수 벡터
사례 연결
학급과 성별에 따른 키 차이 분석
왜 MANOVA냐면
여러 성과지표를 동시에 고려하기 때문이다.
4. 상관관계분석
두 연속형 변수 간의 선형적 관계 분석
두 변수 사이의 직선적 관계 강도를 수치화한다는 뜻이다.
왜 상관계수를 쓰는가?
왜냐하면 공분산은 단위에 의존하기 때문이다.
왜 표준화하냐면
비교 가능하게 만들기 위해서다.
수식

- r 범위 = -1 ~ +1
사례
몸무게와 키의 비례 관계
상관관계 산점도



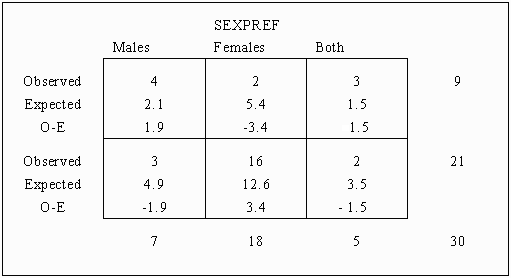
5. 교차분석
범주형 변수들 간의 독립성 분석
범주 × 범주 빈도 비교
왜 카이제곱을 쓰는가?
왜냐하면 기대빈도와 실제빈도 차이를 정량화하기 위해서다.
수식

사례
영양제 복용 여부 × 감기 발생 여부
교차표 구조

정리
| 기법 | 종속변수 유형 | 독립변수 유형 | 목적 |
| 다중회귀 | 연속형 1개 | 연속형 다수 | 값 예측 |
| 로지스틱 | 이진/순서형 | 연속/범주 | 확률 예측 |
| MANOVA | 연속형 2개 이상 | 범주형 | 평균 차이 |
| 상관분석 | 없음 | 연속형 2개 | 선형 관계 |
| 교차분석 | 없음 | 범주형 | 독립성 |
데이터의 차원축소 기법
변수들 간의 상관관계를 분석하여 가지고 있는 의미를 유지하면서(정보 손실 최소화) 변수를 요약하고자 할 때 사용하는 분석 방법은 다음과 같다.
이 문장은 “변수를 줄인다”는 뜻이지만
아무렇게나 줄이는 것이 아니라
상관관계를 이용해서 구조를 압축한다는 뜻이다.
왜 상관관계를 이용하나?
왜냐하면 다변량 데이터에서는
여러 변수들이 서로 겹치는 정보를 담고 있기 때문이다.
왜 겹치는 정보가 생기냐면
현실 현상은 하나의 잠재 원인에 의해
여러 변수로 동시에 나타나는 경우가 많기 때문이다.
예를 들어
습도와 강수량은 서로 관련이 크다.
왜냐하면 수증기 농도가 높으면
강수 확률이 증가하기 때문이다.
따라서 이 둘은 완전히 독립적인 정보가 아니라
부분적으로 같은 구조를 공유한다.
그래서 우리는 묻는다.
“이 겹치는 구조를 하나의 축으로 표현할 수 없을까?”
이 질문이 차원 축소의 출발점이다.
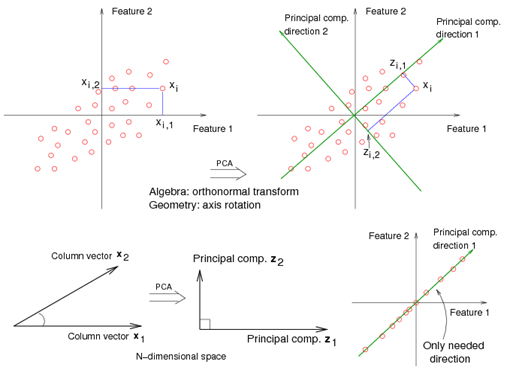
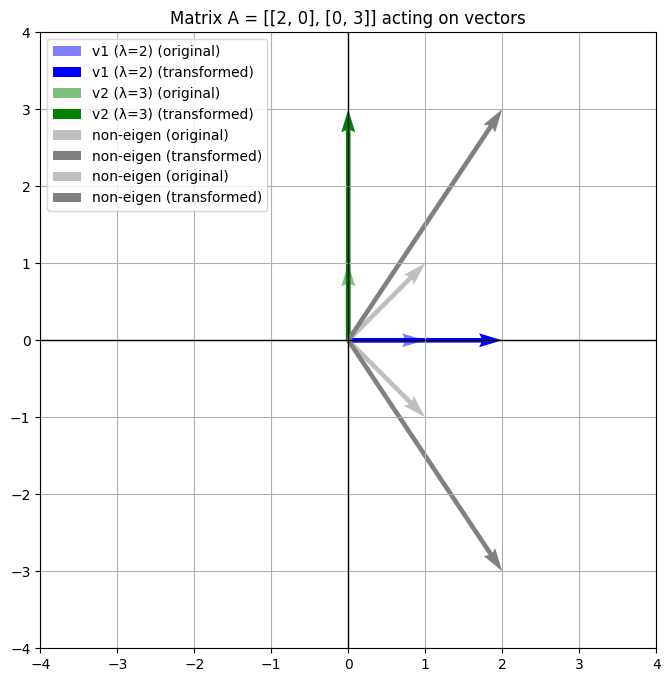
1.주성분분석 (PCA)
고차원 공간(다변량 변수)의 표본들을 선형 연관성이 없는 저차원(새로운 변수) 공간으로 변환하는 기법
고차원 공간이라는 것은
변수가 여러 개인 공간을 말한다.
왜냐하면 변수 하나가 한 축(axis)이 되기 때문이다.
예를 들어
습도(X1), 강수량(X2), 풍속(X3), 태풍지수(X4)
이렇게 4개면 4차원 공간이다.
PCA는 이 4차원 공간의 데이터를
새로운 축 2개로 재구성하는 방법이다.
왜 선형 연관성이 없는 공간으로 변환하나?
왜냐하면 기존 변수들은 서로 상관되어 있기 때문이다.
왜 상관이 문제냐면
중복된 정보를 반복해서 사용하게 되기 때문이다.
PCA는 이렇게 말한다.
“가장 분산이 큰 방향을 첫 번째 축으로 잡자.”
왜 분산이 큰 방향을 잡느냐면
그 방향이 데이터를 가장 잘 설명하는 방향이기 때문이다.
수식 구조

여기서
- Q = 고유벡터 (새로운 축 방향)
- Λ = 고유값 (분산 크기)
왜 고유벡터가 축이 되느냐면
공분산 행렬의 고유벡터는
데이터 분산이 극대화되는 방향을 나타내기 때문이다.
기하학적 의미
기존 축이 기울어져 있는 데이터 구름이 있다면
PCA는 그 구름의 가장 긴 방향으로 좌표계를 돌린다.
PCA 시각화


사례 연결
습도 + 강수량 → 하나의 기상축
풍속 + 태풍 → 또 다른 축
왜냐하면
풍속이 빠르면 태풍 발생 가능성이 높기 때문이다.
즉, 서로 강하게 상관된 변수들은
하나의 주성분으로 묶인다.
2.요인분석 (FA)
데이터에 관찰할 수 있는 잠재적 변수가 존재한다고 가정
PCA는 단순히 “분산 최대 방향”을 찾는 것이고
요인분석은 “보이지 않는 원인이 있다”고 가정하는 것이다.
왜 잠재요인을 가정하나?
왜냐하면 관측 변수들은
숨은 원인의 결과일 가능성이 크기 때문이다.
예를 들어
시험 점수(수학, 영어, 과학)가 높다 →
그 이유는 “학습능력”이라는 보이지 않는 요인 때문일 수 있다.
수식

- X = 관측변수
- F = 잠재요인
- Λ = 요인적재량
- ε = 오차
왜 적재량을 보느냐면
각 변수가 어떤 요인에 얼마나 기여하는지를 보여주기 때문이다.
PCA와 차이
왜 PCA는 분산 중심이고
요인분석은 구조 중심이냐면
PCA는 데이터 압축이 목적이고
요인분석은 해석이 목적이기 때문이다.
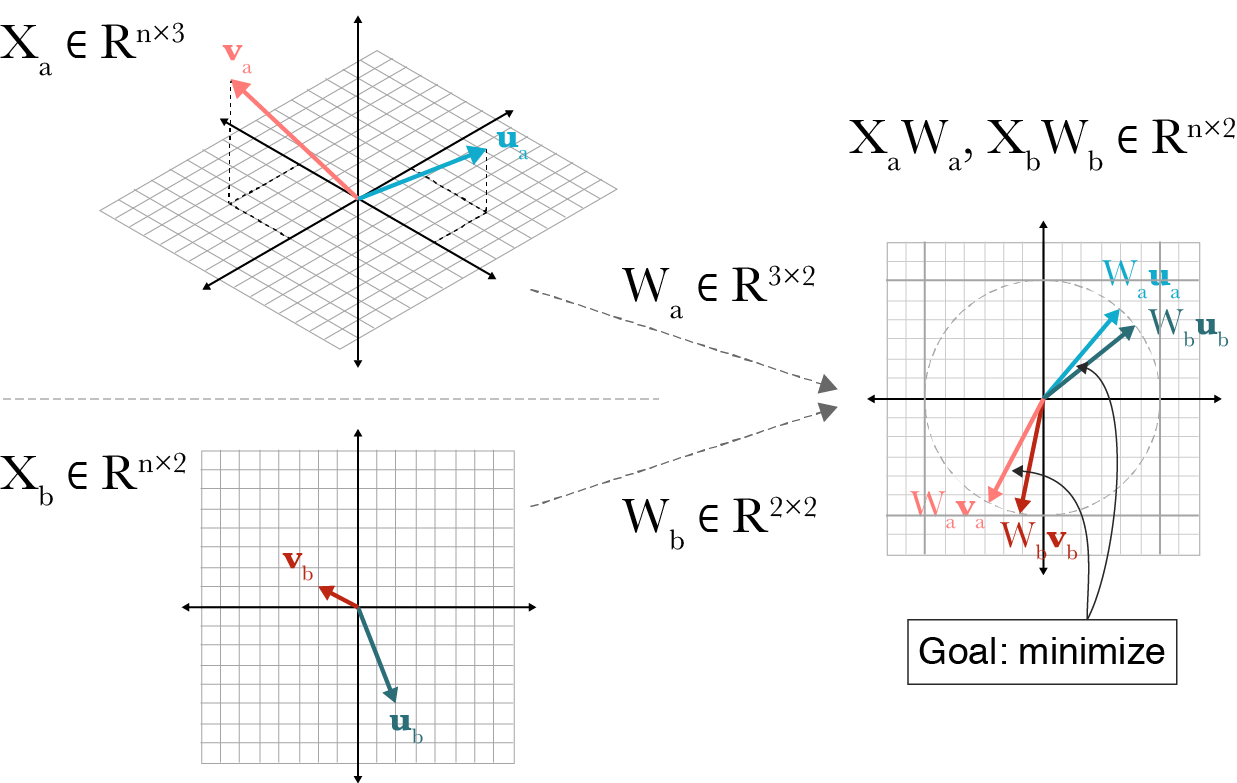
3. 정준상관분석 (CCA)
두 개의 변수 집단 간의 선형성 상관관계를 파악
여기서는 변수 하나가 아니라
변수 집단 A와 변수 집단 B의 관계를 본다.
예:
집단 A: 온도, 농도, 시간
집단 B: 반응 후 생성량, 잔존량
왜 집단 대 집단을 보나?
왜냐하면 현실 문제는
한 변수 대 한 변수 관계로 끝나지 않기 때문이다.
화학반응은
온도 하나로 설명되지 않고
농도와 시간과 함께 작용하기 때문이다.
수식 구조

왜 이렇게 하느냐면
두 집단을 각각 하나의 축으로 압축한 뒤
그 축들 간 상관을 최대화하려는 것이다.
CCA 구조 시각화
세 기법의 철학적 차이
| 기법 | 초점 | 무엇을 줄이나 | 왜 |
| PCA | 분산 | 변수 차원 | 중복 정보 제거 |
| FA | 잠재구조 | 변수 의미 | 숨은 요인 해석 |
| CCA | 집단 간 관계 | 집단 축 | 두 시스템 연결 |
차원 관점에서 본 구조
PCA → 하나의 데이터 공간 안에서 축 회전
FA → 보이지 않는 축을 가정
CCA → 두 공간을 연결하는 축 찾기
케이스 차원축소 기법(개체 분류)
변수들이 가지는 값들의(개체들의) 유사성을 이용하여 분류하고자 할 때 사용하는 분석 방법은 다음과 같다.
여기서는 변수 자체를 줄이는 것이 아니라
“개체들(행, row)”을 중심으로 본다는 뜻이다.
왜냐하면 데이터 행렬에서

열(column)은 변수이고
행(row)은 개체이기 때문이다.
여기서는 열이 아니라 행과 행 사이의 거리를 본다.
왜 개체 간 유사성을 보나?
왜냐하면 현실에서는
“누가 누구와 비슷한가?”가 중요하기 때문이다.
왜 고객을 묶어야 하느냐면
비슷한 행동 패턴을 가진 집단을 찾기 위해서다.
왜 집단을 찾아야 하느냐면
마케팅, 위험 관리, 정책 결정은 집단 단위로 이루어지기 때문이다.
1. 다차원척도법 (MDS)
개체들 사이의 유사성, 비유사성을 측정하여 2차원 또는 3차원 공간상에 점으로 표현
고차원 데이터가 있다.
예를 들어 한 도시가
- 평균기온
- 습도
- 인구
- 소득
같은 10개의 변수로 표현된다면
각 도시는 10차원 공간의 점이다.
MDS는 묻는다.
“도시들 간 거리만 알고 있다면, 이걸 2차원에 그릴 수 없을까?”
왜 거리 기반인가?
왜냐하면 개체 유사성은
변수 자체가 아니라
개체 간 차이의 크기로 정의되기 때문이다.
보통 유클리디안 거리:

왜 거리 제곱을 합하느냐면
각 변수 차이를 종합하기 위해서다.
MDS의 핵심
MDS는 거리 행렬 D를 입력으로 받아
저차원 좌표 Y를 찾는다.

왜 최소화하느냐면
원래 거리 구조를 최대한 보존하기 위해서다.
기하학적 의미
고차원 공간의 점들을
평면 위로 눌러서 펼친다.
MDS 시각화

사례 연결
각 도시별 위치에 따른 유사성 분석
왜 MDS냐면
도시 간 차이(거리)를 시각적으로 보고 싶기 때문이다.
2. 판별분석 (LDA 중심)
선형판별분석: 데이터 분포를 학습해 결정경계를 만들어 데이터를 분류
여기서는 이미 집단 라벨이 존재한다.
예:
- 정상 카드 사용
- 부정 카드 사용
왜 분포를 학습하나?
왜냐하면 각 집단은
특정 확률분포를 따른다고 가정하기 때문이다.
왜 가우시안 분포를 가정하느냐면
수학적으로 해가 깔끔하게 나오기 때문이다.
수식 구조
LDA는 두 집단 평균 차이를
분산 대비 최대화한다.

왜 이걸 최대화하느냐면
집단 간 거리는 멀고
집단 내부는 촘촘하게 만들기 위해서다.
PCA와 차이
왜 PCA는 분산 최대 방향이고
LDA는 분리 최대 방향이냐면
PCA는 라벨을 모르고
LDA는 라벨을 알고 있기 때문이다.
즉,
PCA = 표현 최적화
LDA = 분류 최적화
LDA 결정경계 시각화
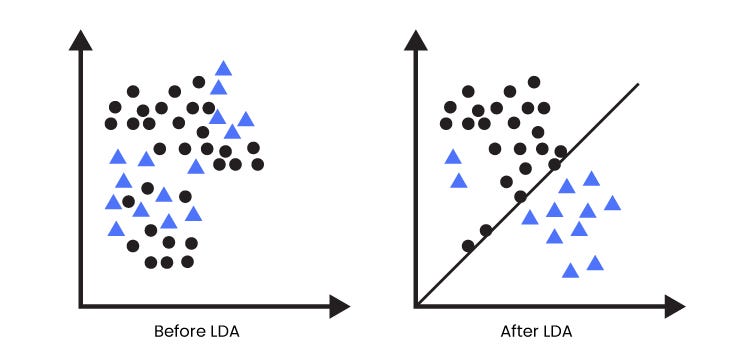
사례 연결
고객 카드 사용금액, 업종, 장소 → 부정 사용 예측
왜 LDA냐면
두 집단을 가장 잘 구분하는 축을 찾기 때문이다.
구조 비교
| 기법 | 초점 | 입력 | 출력 |
| MDS | 거리 보존 | 거리행렬 | 저차원 좌표 |
| LDA | 집단 분리 | 라벨 포함 데이터 | 분류 경계 |
차원 관점에서 정리
- MDS는 “거리 구조 유지”
- LDA는 “집단 분리 최대화”
- 둘 다 행 중심(개체 중심) 분석
시각화 기반 다변량 데이터 탐색 방법
산점도행렬은 여러 개의 연속형 변수에 대해서 각각 쌍을 이루어 산점도를 그려서 한꺼번에 변수 간의 상관관계(상관계수 이용)를 일목요연하게 볼 수 있다.
“산점도행렬(scatter plot matrix)”이란
여러 개의 연속형 변수들을
2개씩 짝지어서 모든 가능한 조합의 산점도를
하나의 격자(grid) 형태로 동시에 보여주는 시각화 기법이라는 뜻이다.
왜 각각 쌍을 이루는가?
왜냐하면 연속형 변수들 간의 관계는
두 변수 사이에서 가장 직관적으로 보이기 때문이다.
왜 두 변수 단위로 보느냐면
3차원 이상이 되면 인간의 시각 인지가 급격히 떨어지기 때문이다.
즉,
고차원 데이터를 이해하기 위해
2차원 단위로 분해해서 보는 전략이다.
왜 상관관계를 한꺼번에 보려는가?

즉, 변수 5개면
10개의 산점도가 필요하다.
따라서 하나씩 따로 보면
패턴을 비교하기 어렵기 때문에
행렬 구조로 동시에 본다.
행렬을 이용해 데이터 분포와 변수들의 밀접도, 그리고 자료 분포에 존재하는 패턴을 식별할 수 있고
여기서 행렬(matrix)은
가로축 변수 × 세로축 변수의 조합으로
격자 형태를 만든다는 뜻이다.
예를 들어
X1, X2, X3가 있다면
| X1 | X2 | X3 | |
| X1 | - | X1 vs X2 | X1 vs X3 |
| X2 | X2 vs X1 | - | X2 vs X3 |
| X3 | X3 vs X1 | X3 vs X2 | - |
왜 행렬 구조가 중요한가?
왜냐하면 행과 열을 교차시키면
모든 쌍 관계를 빠짐없이 포함할 수 있기 때문이다.
왜 밀접도를 본다고 했느냐면
산점도의 기울기와 퍼짐 정도가
공분산과 상관계수의 시각적 표현이기 때문이다.
수식 연결
상관계수:

왜 이 수식이 중요하냐면
산점도에서 점들이 대각선 방향으로 모이면
분자값이 커지기 때문이다.
즉, 산점도 모양이 수식으로 연결된다.
패턴 식별
왜 패턴을 볼 수 있느냐면
- 직선 형태 → 선형 상관
- 곡선 형태 → 비선형 관계
- 군집 형태 → 집단 구조
- 퍼짐 정도 차이 → 이분산성
이 모두가 산점도에서 드러나기 때문이다.
대각선 위치는 동일한 변수에 대한 산점도의 위치이므로 비워두거나 각 변수의 히스토그램 등으로 표기할 수 있다.
행과 열이 같은 위치
즉 (X1, X1) 같은 칸은
자기 자신과의 관계이기 때문에
산점도를 그릴 의미가 없다.
왜 히스토그램을 넣는가?
왜냐하면 단변량 분포도
같이 보고 싶기 때문이다.
왜 단변량 분포가 중요하냐면
상관관계는 분포 형태에 영향을 받기 때문이다.
예를 들어
왜도가 심하면
상관계수가 왜곡될 수 있다.
히스토그램 수식 연결
확률밀도함수 근사:

왜 이런 걸 보느냐면
분포가 대칭인지 왜도 있는지 확인하기 위해서다.
산점도행렬 시각화 예시
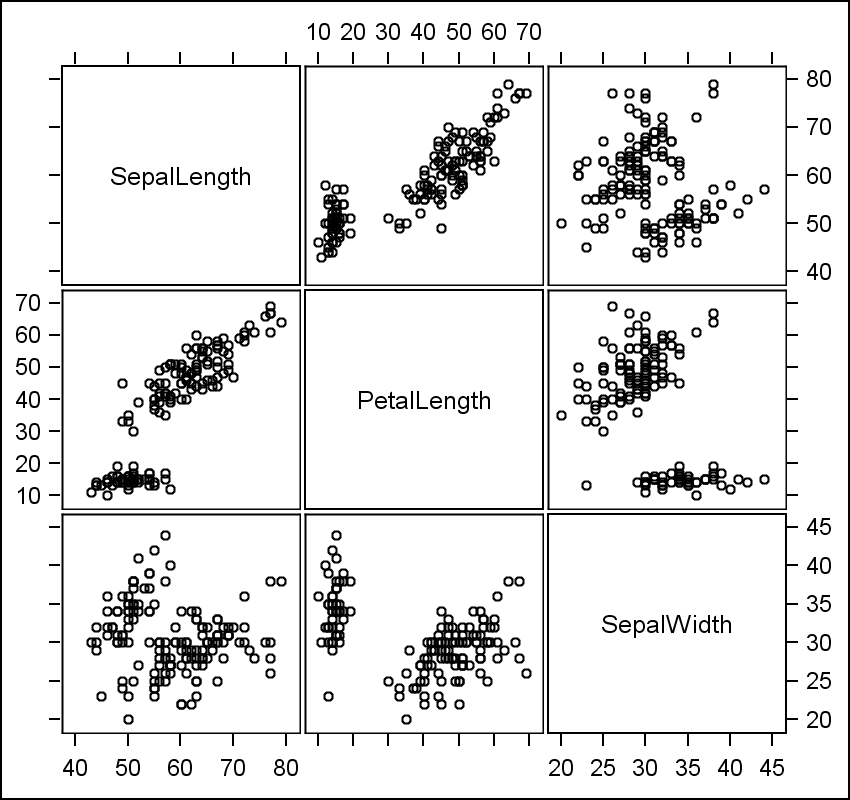

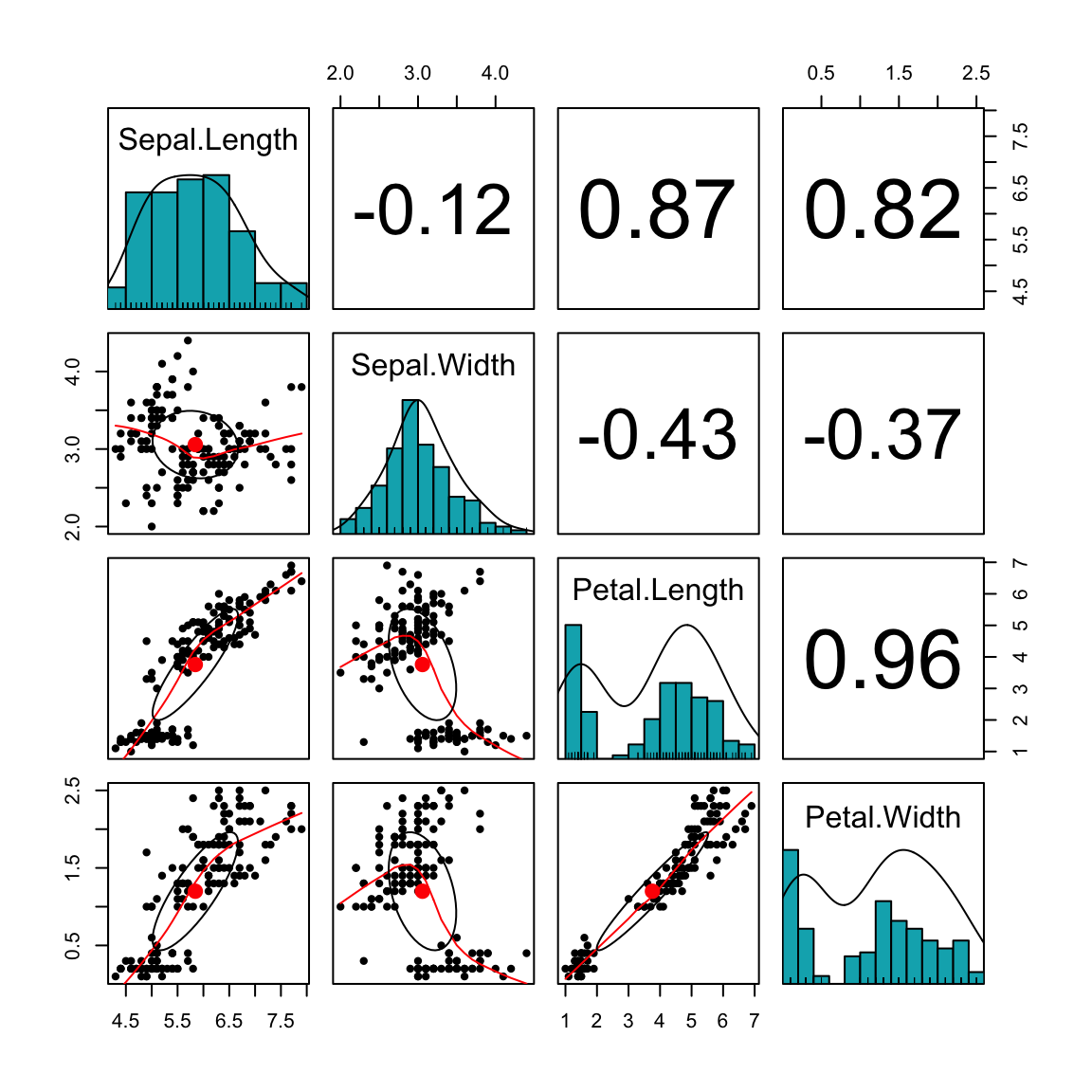
기하학적 의미
산점도행렬은
고차원 공간 데이터를

로 부분 투영(projection)한 것이다.
왜 부분 투영이냐면
각 쌍이 전체 공간의 단면(slice)이기 때문이다.
즉, 산점도행렬은
고차원 구조를 2차원 조각들로 분해해서
전체를 이해하려는 전략이다.
정리
- 변수 p개 → p×p 행렬
- 대각선 → 단변량 분포
- 비대각선 → 이변량 관계
- 상관계수 ↔ 산점도 기울기
- 분산 ↔ 퍼짐 정도
- 군집 ↔ 집단 구조
산점도는 무엇을 그린 것인가?
산점도(Scatter Plot)는
두 개의 연속형 변수 (X, Y)를
2차원 좌표평면에 점으로 표현한 것이다.
왜 점으로 표현하느냐면
각 개체가 (x_i, y_i)라는 한 쌍의 값을 가지기 때문이다.
수식으로 쓰면:

왜 이런 구조냐면
하나의 관측치는 두 변수의 값을 동시에 가진다는 뜻이기 때문이다.
첫 번째로 보는 것: “방향(Direction)”
산점도를 보면 먼저 점들의 “기울기 방향”을 본다.
왜냐하면 방향이 바로 상관관계의 부호를 나타내기 때문이다.
양의 상관관계
점들이 오른쪽 위 방향으로 증가하면
X가 증가할 때 Y도 증가한다는 뜻이다.
상관계수 수식:

음의 상관관계
점들이 오른쪽 아래 방향이면
X가 증가할 때 Y는 감소한다.
왜 r이 음수가 되느냐면
편차 곱이 서로 반대 부호이기 때문이다.
예시 그림 (양·음 상관 비교)




두 번째로 보는 것: “강도(Strength)”
왜 강도를 보느냐면
관계가 얼마나 밀접한지 판단해야 하기 때문이다.
점들이 직선에 가깝게 모이면
왜 강한 상관이냐면
잔차(오차)가 작기 때문이다.
잔차 수식:

왜 잔차가 작으면 강한 상관이냐면
설명력이 높다는 뜻이기 때문이다.
점들이 흩어져 있으면
왜 약한 상관이냐면
공분산 값이 작아지기 때문이다.
강한 상관 vs 약한 상관



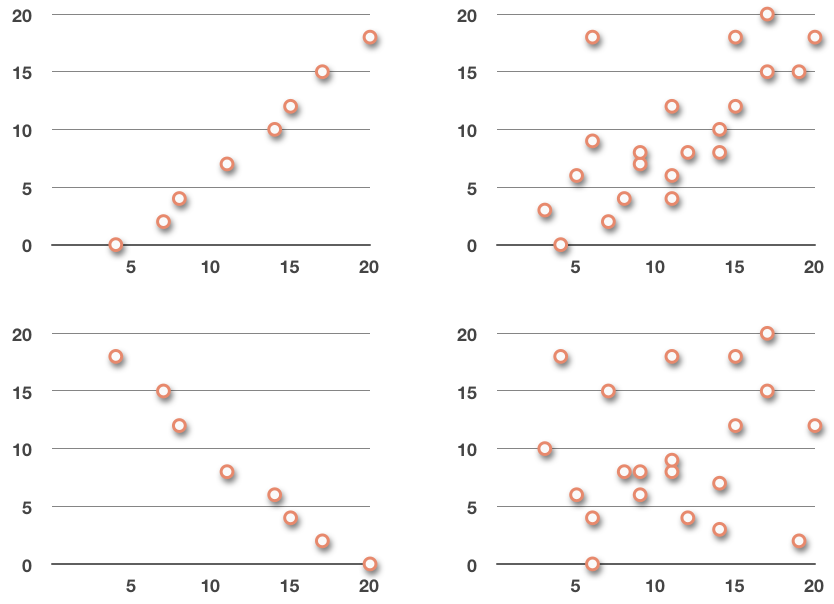
세 번째로 보는 것: “형태(Form)”
왜 형태를 보느냐면
상관계수는 선형관계만 측정하기 때문이다.
직선 형태
왜 직선이면 선형관계냐면
Y가 X의 1차식으로 표현 가능하기 때문이다.

곡선 형태
왜 r이 0에 가까워질 수 있느냐면
선형관계는 없지만 비선형관계가 존재하기 때문이다.
예:

이 경우 산점도는 U자 모양이 된다.
📊선형 vs 비선형



네 번째로 보는 것: “이상치(Outlier)”
왜 이상치를 보느냐면
상관계수는 극단값에 매우 민감하기 때문이다.
왜냐하면 공분산 계산 시
편차 제곱이 포함되기 때문이다.

편차가 크면 곱이 급격히 커진다.
이상치 영향


다섯 번째로 보는 것: “분산 구조”
왜 점들의 퍼짐 모양을 보느냐면
등분산성(homoscedasticity) 가정과 관련 있기 때문이다.
등분산
왜 회귀에서 중요하냐면
오차 분산이 일정해야 통계적 추정이 안정적이기 때문이다.
이분산
왜 문제냐면
표준오차 추정이 왜곡될 수 있기 때문이다.
- 등분산(Homoscedasticity)
→ 집단(또는 X값)에 따라 분산이 같다 - 이분산(Heteroscedasticity)
→ 집단(또는 X값)에 따라 분산이 다르다
왜 중요한데?
통계 검정이나 회귀모형은
기본 가정이 하나 있음:
오차의 분산은 일정해야 한다
이게 바로 등분산 가정
이게 깨지면?
→ 추정은 되지만
→ t값, p값이 왜곡됨
직관적
예를 들어:
X = 공부시간
Y = 시험점수
등분산 상황
공부 1시간 → 점수 흩어짐 정도 5점
공부 5시간 → 점수 흩어짐 정도 5점
→ 분산 일정
이분산 상황
공부 1시간 → 점수 흩어짐 3점
공부 10시간 → 점수 흩어짐 20점
→ X가 커질수록 퍼짐 커짐
이게 이분산.
그림
등분산
*
* *
* *
* *
* *
폭이 일정함
이분산
*
*
* *
* *
* *
* *
점점 퍼짐이 커짐
수식적으로 말하면
회귀모형:

여기서 가정:
등분산이면

모든 i에 대해 동일
이분산이면

각각 다름
왜 문제냐?
OLS(최소제곱법)는
- 계수는 여전히 unbiased (편향 없음)
- BUT
- 분산 추정이 틀림
- 표준오차가 틀림
- t검정, F검정이 틀림
그래서 이분산이면
→ White test
→ Breusch-Pagan test
→ robust standard error 사용
t검정에서 등분산 vs 이분산
두 집단 평균 비교할 때:
등분산 가정 → pooled t-test
이분산 → Welch’s t-test
시험 단골임.
왜 현실에서 이분산 자주 생기냐?
경제 데이터 예:
소득 낮은 사람 → 소비 변동 작음
소득 높은 사람 → 소비 변동 큼
즉, 규모 커질수록 분산 커짐.
정리
| 구분 | 의미 |
| 등분산 | 오차 분산 일정 |
| 이분산 | 오차 분산 일정하지 않음 |
| 영향 | 검정 통계량 왜곡 |
| 해결 | robust SE 사용 |
등분산 vs 이분산




산점도 읽는 6단계 순서
- 방향 (양/음)
- 강도 (밀집 정도)
- 형태 (선형/비선형)
- 이상치 존재 여부
- 분산 구조
- 집단 패턴(군집)
산점도는
“공분산 구조를 시각화한 그림”이다.
왜냐하면
기울기 = 공분산 부호
퍼짐 = 분산 크기
밀집도 = 상관계수 크기
이기 때문이다.
체르노프페이스(Chernoff Face)는 다차원 통계 데이터를 사람의 얼굴 이미지를 이용하여 시각적으로 표현하는 방법이다.
이 문장은 “다차원 통계 데이터” 즉 여러 개의 변수를
숫자 그래프 대신 “사람 얼굴”의 각 부분으로 대응시켜
한 번에 직관적으로 보여주는 시각화 기법이라는 뜻이다.
왜 얼굴을 사용하는가?
왜냐하면 인간의 뇌는
얼굴을 인식하는 능력이 매우 발달되어 있기 때문이다.
왜 얼굴 인식 능력이 강하냐면
진화 과정에서 사회적 생존을 위해
얼굴의 미세한 차이를 빠르게 구분하도록 발달했기 때문이다.
즉, 숫자 표보다
얼굴 변화가 더 빠르게 인지된다.
- 다차원 데이터 (Multivariate Data)
변수 (p)개를 가진 데이터 - 시각화 (Visualization)
수치 정보를 시각적 요소로 변환하는 과정 - 체르노프 (Herman Chernoff)
이 기법을 제안한 통계학자
수식적 표현
각 얼굴 요소는 변수의 함수로 정의된다.
예를 들어:

왜 함수로 정의하느냐면
각 변수 값을 0~1 범위로 정규화한 뒤
시각적 비율로 변환해야 하기 때문이다.
정규화 수식:

왜 정규화를 하느냐면
각 변수의 단위 차이를 제거하기 위해서다.
얼굴의 가로 너비, 세로 높이, 눈, 코, 입, 귀 등 각 부위를 변수로 대체하여 데이터의 속성을 쉽게 파악할 수 있다.
각 얼굴 구성 요소가 하나의 변수 역할을 한다는 뜻이다.
예를 들어
- 얼굴 가로 너비 → 변수 1
- 얼굴 세로 높이 → 변수 2
- 눈 크기 → 변수 3
- 입 곡률 → 변수 4
왜 각 부위를 변수로 쓰는가?
왜냐하면 얼굴은 여러 독립적인 형태 요소로 구성되어 있기 때문이다.
왜 독립적이냐면
눈 크기와 입 크기는 물리적으로 별개 조절 요소이기 때문이다.
즉, 각 변수는 하나의 얼굴 파라미터가 된다.
데이터 구조 연결
만약 축구선수 능력치가 다음과 같다면:

로 매핑한다.
왜 “쉽게 파악”할 수 있는가?
왜냐하면 인간은
숫자 차이보다 시각적 대비를 빠르게 감지하기 때문이다.
예를 들어
머리 높이가 매우 크면
눈으로 즉시 “이 선수는 해당 능력이 높다”는 걸 인식한다.
축구선수의 능력치를 체르노프페이스로 표현한다고 했을 때, 위 그림에서 축구선수 호나우도는 세 명의 선수 중 머리 높이가 가장 높고, 머리 너비가 가장 넓은 것으로 보아 골과 도움이 많음을 알 수가 있다.
여기서는
특정 변수(골, 도움)를
머리 높이, 머리 너비에 대응시켰다는 뜻이다.
즉,

왜 이런 해석이 가능한가?
왜냐하면 시각적 요소가
숫자 크기에 비례하도록 설계되어 있기 때문이다.
왜 비례시키느냐면
시각적 왜곡을 방지하기 위해서다.
예:
골 수가 많으면
머리 세로 길이가 길어진다.
도움이 많으면
머리 가로 폭이 넓어진다.
기하학적 관점

여기서 (k)는 얼굴 구성 요소 수이다.
체르노프 페이스 예시 시각화




체르노프 페이스의 장단점
장점
왜 장점이 있느냐면
다차원 데이터를 직관적으로 한눈에 비교 가능하기 때문이다.
단점
왜 단점이 있느냐면
정량적 비교가 어렵고
과도한 차원에서는 인지 과부하가 발생하기 때문이다.
본질
체르노프 페이스는
수치 → 시각 기호 변환이다.
왜 이런 기법이 등장했느냐면
고차원 데이터를 인간이 이해할 수 있는 방식으로
변환하기 위해서다.
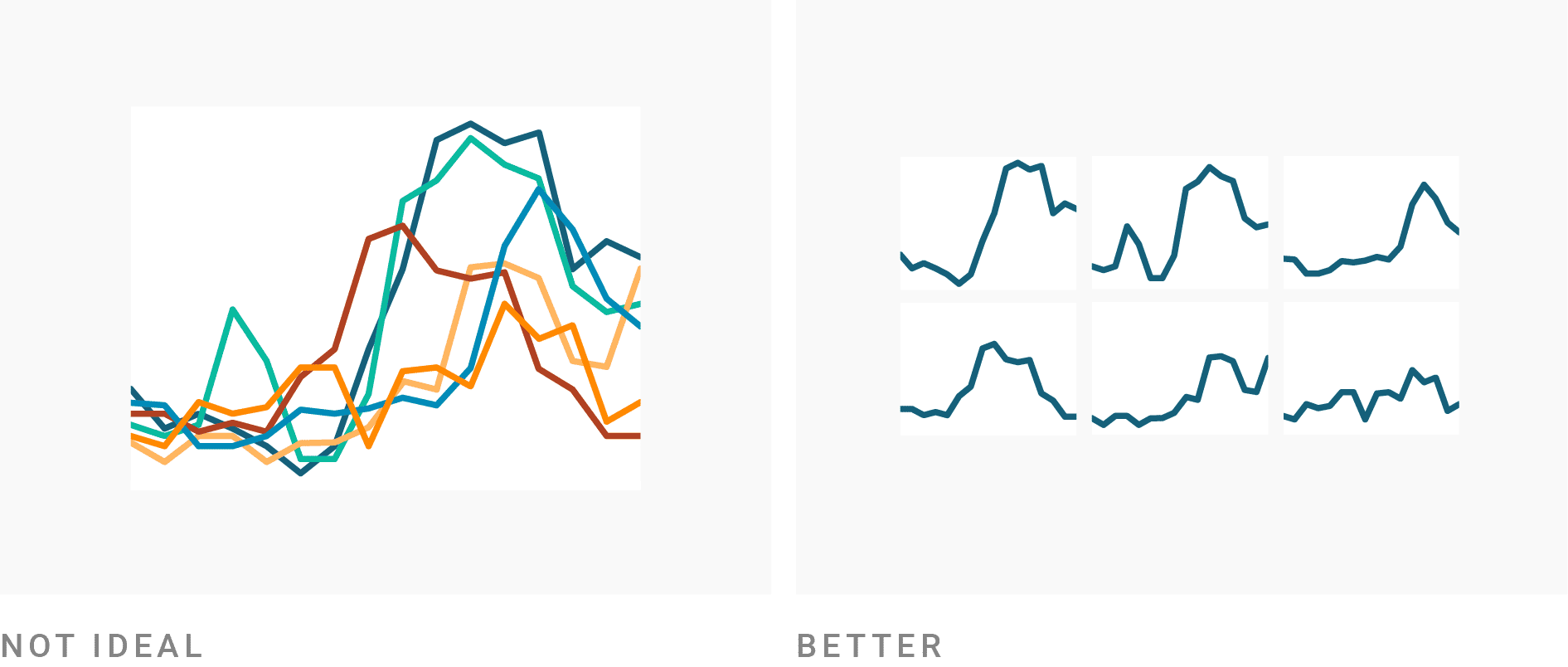
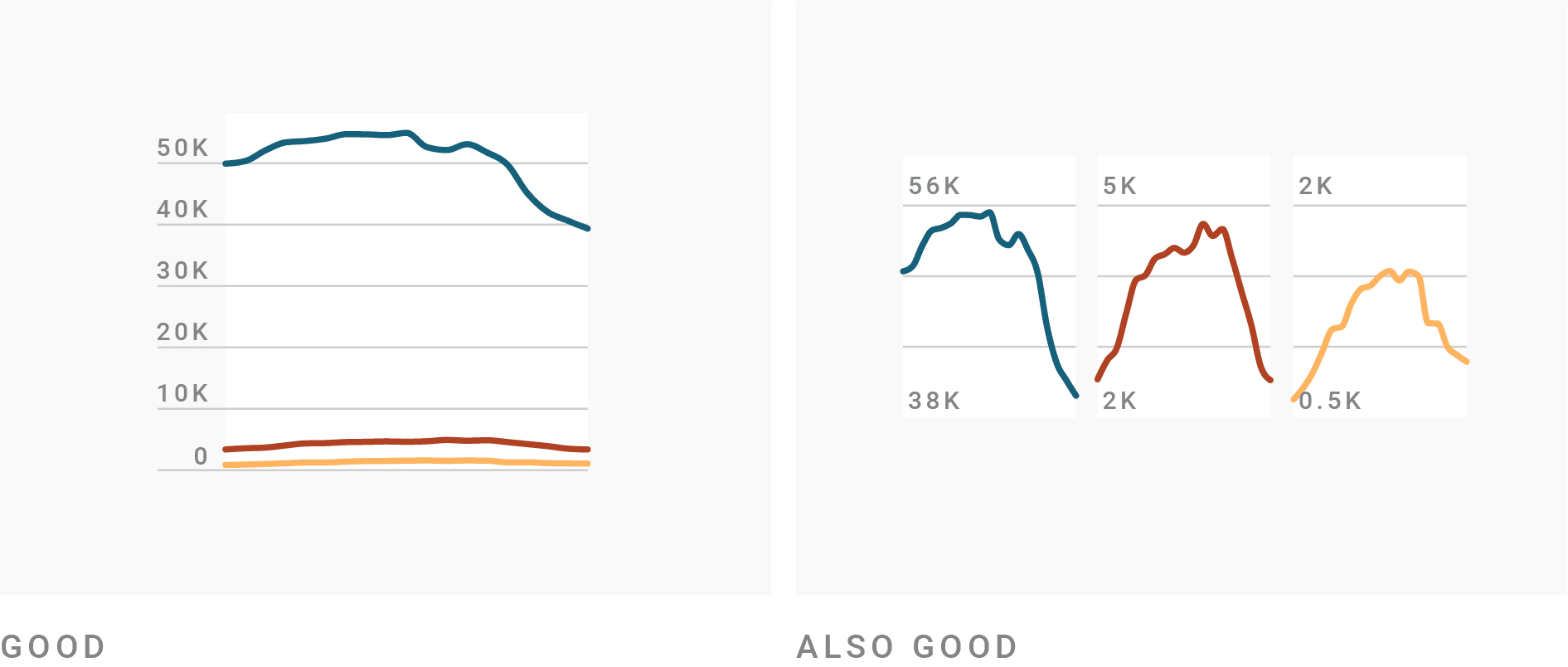
스몰멀티플즈(Small Multiples)는 다수의 데이터로 구성된 복잡한 차트를 정보별로 분리한 뒤 동일한 시각화 차트로 나열하여 매트릭스 형태로 배치함으로써 전체적인 패턴을 파악하거나 시간적인 변화의 추세를 알아보는데 적합한 차트이다.
이 문장은 “복잡한 하나의 차트”를
그대로 보여주는 대신
정보 단위로 나누어
같은 형태의 작은 차트 여러 개로 배치한다는 뜻이다.
왜 분리하는가?
왜냐하면 하나의 차트에
너무 많은 정보가 겹치면
인지 부하(cognitive load)가 증가하기 때문이다.
왜 인지 부하가 문제냐면
사람은 동시에 여러 시각 정보를 비교할 때
겹침(overplotting)이 생기면
패턴을 구별하기 어려워지기 때문이다.
즉, 정보 분리는 가독성을 높이기 위한 전략이다.
왜 동일한 시각화 차트로 나열하는가?
왜냐하면 비교를 가능하게 하려면
축 스케일과 표현 방식이 동일해야 하기 때문이다.
만약 각 차트의 축 범위가 다르면
패턴 비교가 왜곡되기 때문이다.
수학적으로 보면
각 차트는 동일한 함수 형태를 공유한다.

i는 그룹,
t는 시간 또는 범주이다.
왜 동일한 함수 구조를 유지하느냐면
형태 차이만 비교하기 위함이다.
왜 매트릭스 형태로 배치하는가?
왜냐하면 행과 열로 정렬하면
시각적으로 정돈된 구조를 제공하기 때문이다.
왜 행렬 구조가 직관적이냐면
인간은 격자 구조를 빠르게 스캔할 수 있기 때문이다.
전체적인 패턴 파악
왜 작은 차트 여러 개가
전체 흐름을 보여주느냐면
각 패턴을 독립적으로 본 뒤
공통 경향을 비교할 수 있기 때문이다.
예를 들어
지역별 매출 추세를 12개 도시로 나누면
각 도시의 상승/하락 형태를 한눈에 비교할 수 있다.
차트의 종류는 거의 모든 차트를 적용할 수 있어서 바차트나 라인차트와 같은 기본 차트에서 상세한 정보의 표시를 생략한 채 막대나 선의 패턴만을 여러 개 배치하기도 하고
여기서 핵심은
차트 종류가 제한되지 않는다는 것이다.
즉, 시각화 유형은 동일하게 유지하면서
데이터만 분리한다는 뜻이다.
왜 상세 정보를 생략하는가?
왜냐하면 목적이 “비교”이기 때문이다.
왜 세부 수치를 생략하느냐면
정밀한 수치 읽기가 아니라
형태 비교가 핵심이기 때문이다.
이를 “pattern recognition”이라고 한다.
수식적 관점
예를 들어

을 동일 축 위에
여러 패널로 나누어 배치하는 것이다.
라인차트 스몰멀티플즈 예시
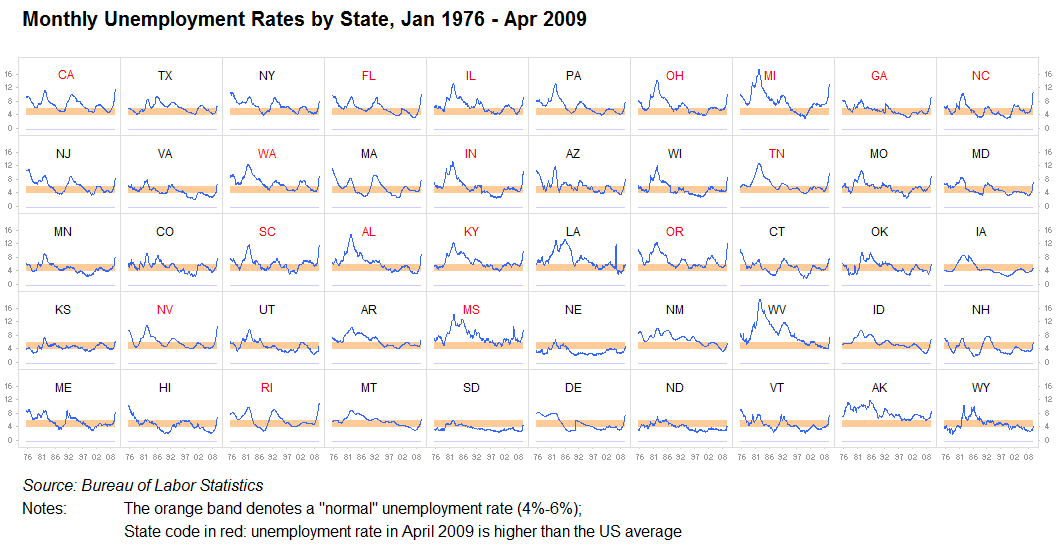
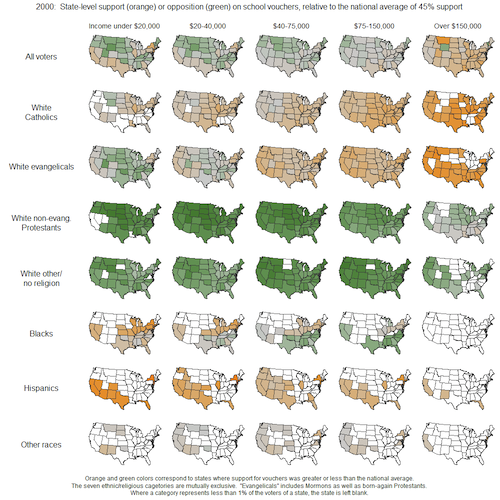
또는 지도와 같이 2차원 이상의 데이터를 포함한 시각화를 여러 개 배치하는 등 다양한 방법으로 활용된다.
여기서는 단순 선그래프뿐 아니라
지도(map) 같은 공간 시각화도
작게 나누어 배치할 수 있다는 뜻이다.
왜 지도도 가능한가?
왜냐하면 스몰멀티플즈는
“차트 유형”이 아니라
“배치 전략(layout strategy)”이기 때문이다.
즉, 동일 구조 반복이 핵심이다.
공간 데이터 수식적 관점
지도는 보통

을 나열하는 구조다.
지도 스몰멀티플즈 예시
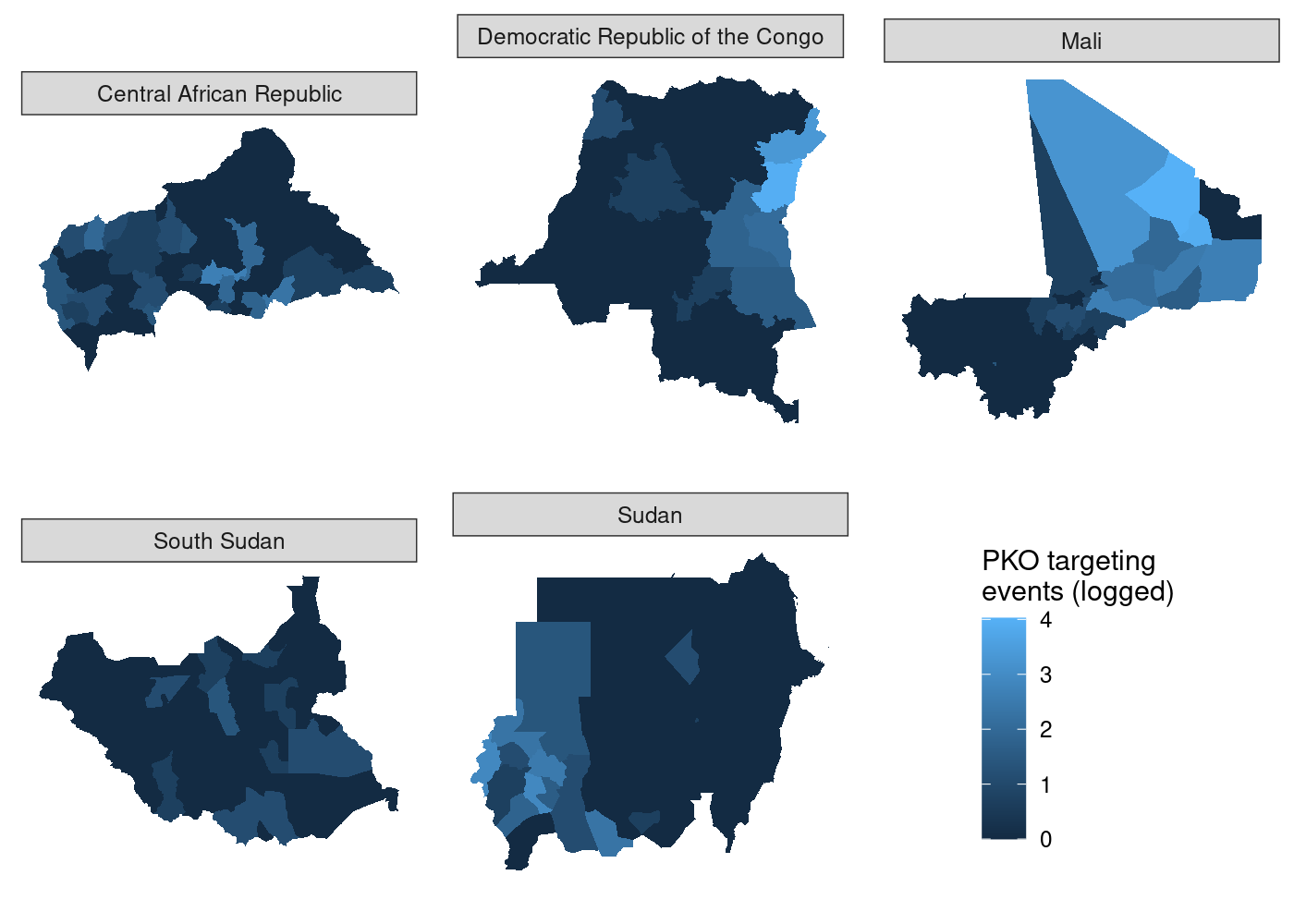

왜 스몰멀티플즈가 강력한가?
왜냐하면
- 겹침 제거
- 비교 용이
- 패턴 강조
이 세 가지를 동시에 만족하기 때문이다.
왜 이것이 중요하냐면
다변량 데이터는
단일 차트로는 구조 파악이 어렵기 때문이다.
본질
스몰멀티플즈는
고차원 데이터를
“반복 구조”로 분해하는 전략이다.
수학적으로 보면

를
p개의 작은 시각화로 나누는 것이다.
.
선버스트차트(Sunburst chart)와 트리맵(Tree map)은 계층 구조로된 다변량 데이터를 분석하는데 적합한 방법이다.
이 문장은 데이터가 단순한 평면 구조가 아니라
“계층 구조(hierarchical structure)”를 가질 때
이를 시각적으로 표현하는 대표적인 방법이
선버스트차트와 트리맵이라는 뜻이다.
왜 계층 구조에서 적합한가?
왜냐하면 계층 구조는
부모-자식 관계(parent-child relationship)로 이루어져 있기 때문이다.
왜 이 관계가 중요하냐면
전체와 부분(part-to-whole) 관계를 동시에 보여줘야 하기 때문이다.
예를 들어
회사 매출
→ 사업부
→ 제품군
→ 개별 제품
이 구조는 트리(Tree) 형태다.
수학적으로 보면 계층 데이터는
트리 그래프 ( G = (V, E) ) 로 표현된다.
- ( V ) = 노드 집합
- ( E ) = 부모-자식 연결
선버스트차트는 하나의 원이 계층 구조의 각 수준을 나타내면서 가장 안쪽에 있는 원이 계층 구조의 가장 높은 수준을 나타내는 차트로, 여러 계층으로 구성된 파이차트라 할 수 있으며, 데이터의 관계와 계층 구조를 통해 각 요소가 결합하여 더 큰 데이터 집단이 되는 과정을 확인할 수 있다.
선버스트차트는
계층을 동심원(concentric circles) 형태로 표현한다는 뜻이다.
가장 중심이 루트(root)이고
바깥쪽으로 갈수록 하위 수준이다.
왜 중심이 최상위인가?
왜냐하면 계층 구조는
상위에서 하위로 분기되는 구조이기 때문이다.
왜 바깥쪽으로 확장하느냐면
시각적으로 “확장(expansion)”의 개념을 전달하기 위해서다.
파이차트와의 관계
왜 여러 계층으로 구성된 파이차트라 하느냐면
각 원형 구간이 비율을 나타내기 때문이다.
각 구간의 각도는 다음과 같이 계산된다.

왜 각도로 표현하느냐면
원 전체가 100%를 의미하기 때문이다.
데이터 결합 과정
왜 “각 요소가 결합하여 더 큰 집단이 되는 과정”을 볼 수 있느냐면
하위 노드의 값이 상위 노드 값에 합산되기 때문이다.
수식적으로:

선버스트차트 예시




트리맵의 시각화 공간은 양적변수에 의해 크기와 순서가 정해지는 사각형으로 분할되며, 트리맵의 계층에서 수준은 다른 사각형을 포함하는 사각형으로 시각화된다.
트리맵은 전체 사각형을
데이터 값 비율에 따라
더 작은 사각형으로 나누는 방식이다.
왜 사각형인가?
왜냐하면 사각형은
공간 효율성이 높기 때문이다.
왜 원보다 효율적이냐면
빈 공간이 적고
면적 계산이 직관적이기 때문이다.
면적 수식
각 사각형 면적은

왜 면적으로 표현하느냐면
면적은 비율을 직접적으로 전달하기 때문이다.
계층 표현 방식
왜 상위 수준이 큰 사각형으로 표현되느냐면
그 안에 하위 사각형들이 포함되기 때문이다.
즉, 포함 관계가 시각화된다.
트리맵 예시



계층에서 동일한 수준에 속하는 각 사각형 집단은 데이터 테이블의 표현식 또는 컬럼을 나타내며, 계층에서 동일한 수준에 속하는 각각의 개별 사각형은 컬럼의 범주를 표현한다.
여기서 수준(level)은
데이터 테이블의 컬럼 계층을 의미한다.
예:
컬럼1: 지역
컬럼2: 제품군
컬럼3: 제품명
왜 동일 수준이 중요한가?
왜냐하면 동일 수준은
같은 범주 체계를 공유하기 때문이다.
즉,
- 지역 수준 → 서울, 부산
- 제품군 수준 → 전자, 식품
이렇게 동일 레벨은 같은 차원이다.
수식적 연결
계층은 보통 다중 인덱스 구조로 표현된다.
Index = (Level1, Level2, Level3)
전체 데이터 중 차지하는 비율을 면적으로 표현하여 각 카테고리를 구성하는 요소가 무엇인지 그 비중은 얼마나 되는지 파악할 수 있다.
트리맵은
면적이 곧 비율이다.
왜 면적이 직관적인가?
왜냐하면 인간은
면적 대비 차이를 빠르게 인식하기 때문이다.
예시 연결
예를 들어
전체 매출 = 100억
전자제품 매출 = 40억

따라서 전체 사각형의 40% 면적을 차지한다.
선버스트 vs 트리맵 비교
| 항목 | 선버스트 | 트리맵 |
| 구조 표현 | 원형 확장 | 사각형 분할 |
| 비율 표현 | 각도 | 면적 |
| 공간 효율 | 낮음 | 높음 |
| 직관성 | 계층 흐름 강조 | 면적 비교 강조 |
본질
둘 다 계층 트리 데이터를
2차원 평면으로 투영(projection)한 것이다.
수학적으로는

이다.
'2. 빅데이터 탐색 > 데이터 탐색' 카테고리의 다른 글
| 추론 통계_ 점추정 (0) | 2026.03.06 |
|---|---|
| 비정형 데이터 탐색 (0) | 2026.02.27 |
| 시공간 데이터 탐색 (0) | 2026.02.27 |
| 시각적 데이터 탐색 (1) | 2026.02.26 |
| 기초 통계량 추출 및 이해 (0) | 2026.02.25 |