
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 소프트웨어
- 출력
- 미래 사회의 단위
- 절차적 사고
- 말 인용
- 프로그래밍
- 컴퓨터
- 소프트웨어 시대
- 패킷트레이서 이용
- 순서도
- 절차적 사고의 장점
- 딥러닝
- 레지스터
- 겁나 많아
- 선택
- 뿌..
- 운영체제의 기능 1. 자원 관리 기능 2. 시스템 보호 3. 네트워크(통신 기능)
- 처리
- 기계어
- 운영체제 서비스
- 운영체제의 미래
- 운영체제의 발달 과정
- 반복 구조 찾기
- gensim 3.7.3 설치 오류
- 장치에 할당할 수 없는 NET ID Broadcast주소
- 공부정리
- 국립과천과학관
- 앨런 튜링
- 해결 방안
- 운영체제 목적
- Today
- Total
hye-_
선형 큐와 원형 큐 본문
| 큐 (Queue) | 스택과 비슷한 삽입과 삭제의 위치가 제한되어있는 유한 순서 리스트이다. 큐는 뒤에서는 삽입만 하고, 앞에서는 삭제만 할 수 있는 구조(First In First Out)이다. |
| 순차 큐 | 1차원 배열을 이용한 큐이다. 큐의 크기는 배열의 크기이다. front와 rear 변수를 두어 첫번째 원소와 마지막 원소의 인덱스를 관리한다. |
| 원형 큐 | 1차원 배열을 사용하면서 논리적으로 배열의 처음과 끝이 연결되어 있다고 가정하고 사용하는 형태이다. 초기 공백상태에서는 front와 rear 변수는 같은 값인 0을 가진다. 공백 상태와 포화 상태 구분을 쉽게 하기 위해서 front가 있는 자리는 사용하지 않고 항상 빈자리로 둔다. |
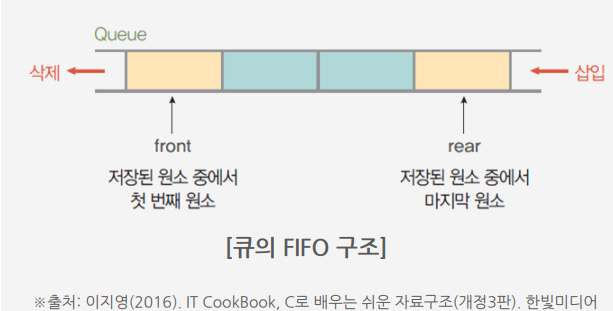
큐 (Queue)
스택과 비슷한 삽입과 삭제의 위치가 제한되어 있는 유한 순서 리스트
큐는 뒤에서는 삽입만 하고, 앞에서는 삭제만 할 수 있는 구조
삽입한 순서대로 원소가 나열되어 가장 먼저 삽입(First-In)한 원소는 맨 앞에 있다가 가장 먼저 삭제(First-out)됨
선입선출 구조(FIFO, First-in-First-out)


스택과 큐의 연산 비교
| 스택 | 큐 |
| 삽입 연산 | |
| 연산자 : push 삽입 위치 : top |
연산자 : enQueue 삽입위치 : rear |
| 삭제 연산 | |
| 연산자 : pop 삭제 위치 : top |
연산자 : deQueue 삭제위치 : front |




순차 큐
1차원 배열을 이용한 큐
○ 큐의 크기 = 배열의 크기
○ 변수 front : 저장된 첫 번째 원소의 인덱스 저장
○ 변수 rear : 저장된 마지막 원소의 인덱스 저장
상태 표현
○ 초기 상태 : front = rear = -1
○ 공백 상태 : front = rear
○ 포화 상태 : rear =n-1
(n : 배열의 크기, n-1 : 배열의 마지막 인덱스 )
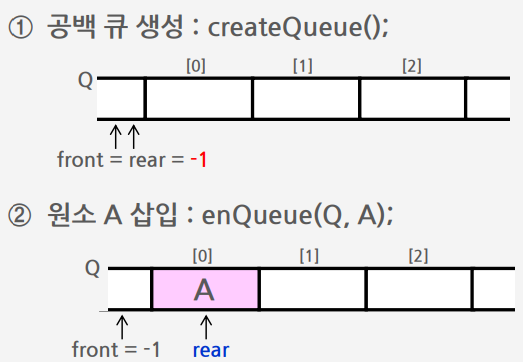
초기 공백 큐 생성 알고리즘



공백 큐 검사 알고리즘과 포화상태 검사 알고리즘

큐의 삽입 알고리즘

마지막 원소의 뒤에 삽입해야 하므로
① 마지막 원소의 인덱스를 저장한 rear의 값을 하나 증가시켜 삽입할 자리 준비
② 수정한 rear 값에 해당하는 배열원소 Q[rear]에 item을 저장
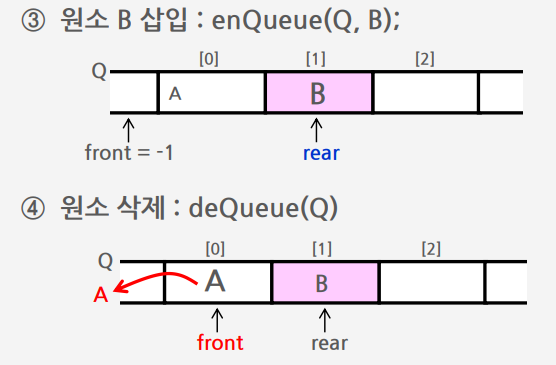
큐의 삭제 알고리즘

가장 앞에 있는 원소를 삭제해야 하므로
① front의 위치를 한자리 뒤로 이동하여 큐에 남아있는 첫 번째 원소의 위치로 이동하여 삭제할 자리 준비
② front 자리의 원소를 삭제하여 반환
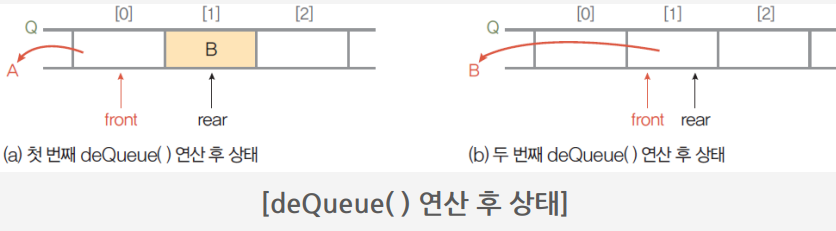
front와 rear의 첨자가 같아지면 공백 큐인것이다.
큐의 검색 알고리즘

가장 앞에 있는 원소를 검색하여 반환하는 연산
① 현재 front의 한자리 뒤(front+1)에 있는 원소, 즉 큐에 있는 첫 번째 원소를 반환
순차 큐의 잘못된 포화상태 인식

큐에서 삽입과 삭제를 반복하면서 그림(a)과 같은 상태일 경우
앞부분에 빈자리가 있지만 rear=n-1 상태이므로 포화상태로 인식하고 더 이상의 삽입을 수행하지 않음
순차 큐의 잘못된 포화상태 인식의 해결 방법 (1)
저장된 원소들을 배열의 앞부분으로 이동시키기
순차자료에서의 이동 작업은 연산이 복잡하여 효율성이 떨어짐
순차 큐의 잘못된 포화상태 인식의 해결 방법 (2)
1차원 배열을 사용하면서 논리적으로 배열의 처음과 끝이 연결되어 있다고 가정하고 사용
원형 큐

원형 큐의 구조
초기 공백 상태
fron = rear = 0
front와 rear의 위치가 배열의 마지막 인덱스 n-1에서 논리적인 다음 자리인 인덱스 0번으로 이동하기 위해서 나머지 연산자 mod를 사용
3 ÷ 4 = 0... 3 (몫=0, 나머지=3)
3 mod 4 = 3
순차 큐와 원형 큐의 비교
| 순차 큐 | 큐 |
| 삽입 위치 | |
| rear = rear + 1 | rear = (rear + 1) mod n |
| 삭제 위치 | |
| front = front + 1 | front = (front + 1 ) mod n |
사용조건
공백 상태와 포화 상태 구분을 쉽게 하기 위해서 front가 있는 자리는 사용하지 않고 항상 빈자리로 둠
초기 공백 원형 큐 생성 알고리즘


○ 크기가 n인 1차원 배열 생성
○ front와 rear을 0으로 초기화
원형 큐의 공백상태 검사 알고리즘과 포화상태 검사 알고리즘

원형 큐의 상태에 따른 front와 rear의 관계
| 구분 | 조건 |
| 공백 상태 | front=rear |
| 포화상태 | (rear+1) mod n=front |
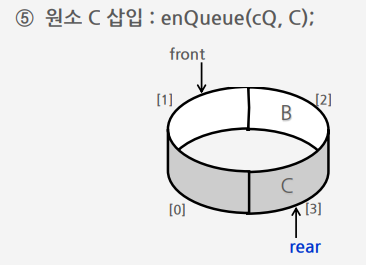
원형 큐의 삽입 알고리즘

○ rear의 값을 조정하여 삽입할 자리를 준비
rear ← (rear+1)mod n;
○ 준비한 자리 cQ[rear]에 원소 item을 삽입
원형 큐의 삭제 알고리즘

○ front의 값을 조정하여 삭제할 자리를 준비
○ 준비한 자리에 있는 원소 cQ[front]를 삭제하여 반환
크기가 4인 원형 큐에서 큐를 생성하고 삽입.삭제하는 연산 과정




'CS > 자료구조' 카테고리의 다른 글
| 트리와 이진 트리 (0) | 2024.07.03 |
|---|---|
| 연결 큐와 데크 (0) | 2024.07.03 |
| 스택의 응용 (0) | 2024.06.29 |
| 원형 연결 리스트와 이중 연결 리스트 (0) | 2024.06.27 |
| 단순 연결 리스트 연산 (0) | 2024.06.26 |



