
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 장치에 할당할 수 없는 NET ID Broadcast주소
- 순서도
- 해결 방안
- 기계어
- 딥러닝
- 뿌..
- 컴퓨터
- 운영체제 목적
- 공부정리
- 앨런 튜링
- 절차적 사고
- 레지스터
- 소프트웨어
- 절차적 사고의 장점
- 미래 사회의 단위
- 프로그래밍
- 운영체제 서비스
- 소프트웨어 시대
- 반복 구조 찾기
- 국립과천과학관
- 패킷트레이서 이용
- 처리
- 선택
- gensim 3.7.3 설치 오류
- 운영체제의 미래
- 출력
- 운영체제의 기능 1. 자원 관리 기능 2. 시스템 보호 3. 네트워크(통신 기능)
- 말 인용
- 운영체제의 발달 과정
- 겁나 많아
- Today
- Total
hye-_
2. 정렬, 해싱 - 37. 검색과 해싱 본문
37. 검색과 해싱
1. 검색 방식 종류
2. 해싱 함수의 종류
검색(Search)의 정의
기억 공간 내 기억된 자료 중에서 주어진 조건을 만족하는 자료를 찾는 것이다.
1. 검색 방식의 종류
1. 이분 검색(Binary Search 이진 검색)의 특징
- 이분 검색을 실행하기 위한 전제 필수 조건은 자료가 순차적으로 정렬되어 있어야 한다. (오름차순이든 내림차순이든)
- 탐색 효율이 좋고 탐색 시간이 적게 소요된다.
- 비교 횟수를 거듭할 때마다 검색 대상이 되는 데이터의 수가 절반으로 줄어든다.
이분 검색 예 ) 1 3 6 7 8 14 19 중 6을 찾고 싶을 때
1. 총 7 배열이므로 (1 + 7)/2를 해준다. 4가 나온다.
2. 4번째 배열 7에 가서 6이 물어본다 ' 네가 나냐 ? 너가 6이냐?' 또 물어본다 '네가 나보다 크냐?'
3. '응 너보단 커'라고 하면 4번째 배열 포함 뒤에 있는 배열 7 8 14 19를 버린다.
4. 남은애들끼리 진행한다. 1 3 6
5. (1 +3)/2 = 2, 2번째 배열 3에 가서 6이 물어본다 '너 나냐?' 또 물어본다 '네가 나보다 크냐?'
6. '아니 니보단 작아'라고 하면 앞에 있는 배열 1 3을 버린다.
7. 그러면 3번째 배열에 6이 존재하는 것을 찾을 수 있다.
그래서, 앞과 뒤 배열을 다 버리기 때문에 오름차순이든, 내림차순이든 꼭 정렬이 되어있어야 되는 것이다.
2. 선형 검색 (Linear Search)
- 주어진 자료에서 원소를 첫 번째 레코드부터 순차적으로 비교하면서 해당키 값을 가진 레코드를 찾아내는 가장 간단한 검색 방법이다.
- 데이터를 특별히 조직화할 필요가 없고 다양한 상황에서도 사용될 수 있는 장점이 있지만 n개의 입력 자료에 대해서 평균적으로 (n+1)/2번의 비교를 해야 하므로 비효율적이다.
3. 피보나치 검색 (Fibonacco Search)
- 이진 검색과 비슷한 원리로, 비교 대상 기준을 피보나치수열로 결정한다.
# 피보나치 수열
1, 2, 3, 5, 8, 11...로 앞의 두 수의 합이 다음번 값이 된다.
4. 블록 검색 (Block Search)
전체 레코드를 일정한 블록으로 분리한 뒤 각 블록 내의 키값을 순서대로 비교하여 원하는 값을 찾는 기법이다.
5. 이진 트리 검색 (Binary Tree Search)
레코드를 2진 트리로 구성하여 검색하는 방식으로 데이터를 입력하는 순서대로 첫 번째 값을 근노드로 지정하고 근노드보다 작으면 왼쪽, 크면 오른쪽에 연결하여 구성한다.
2. 해싱 함수의 종류
키 값을 해시 테이블의 홈주소로 반환하는 함수
1. 제산 방법 (Division Method)
해싱 함수 기법에서 키값을 양의 정수인 소수로 나누어 나머지를 홈주소로 취하는 방법이다.
2. 중간 제곱 방법 (Mid-Square Method)
- 레코드 키값을 제곱하고 나서 그 중간 부분의 값을 주소로 계산하는 방법이다.
- 해시 테이블의 크기에 따라서 중간 부분의 적당한 자릿수를 선택할 수 있다.
- 비트 단위로 n자릿수를 중간 위치 자릿수로 가정하면 해시 테이블의 크기는 2n이다.
3. 중첩 방법(Folding Method)
해싱 함수 중 주어진 키를 여러 부분으로 나누고, 각 부분의 값을 더하거나 배타적 논리합 (XOR : Exclusive OR) 연산을 통하여 나온 결과로 주소를 취하는 방법이다.
4. 기수 변환 방법 (Radix Conversion Method)
해싱 함수 기법 중 어떤 진법으로 표현된 주어진 레코드 키값을 다른 진법으로 간주하고 키값을 변환하여 홈 주소로 취하는 방식이다.
5. 계수 분석 방법 (Digit Analysis Method)
주어진 모든 키 값들에서 그 키를 구성하는 자릿수들의 분포를 조사하여 비교적 고른 분포를 보이는 자릿수들을 필요한 만큼 택하는 방법을 취하는 해싱 함수 기법이다.
컴퓨터는 전기로 이루어져 있다.
전기에 논리적인 규정은 딱 두 가지밖에 없다 on/off
그래서 우리가 전기를 이용해서 컴퓨터를 작동시키기 때문에 컴퓨터는 이진수를 배워야 된다.
이 이진수를 가지고 모든 연산을 다한다. 이것을 명제라 고한다. 참/거짓
컴퓨터를 맨 처음에 설계할 때 '전기가 들어가고 빼고 밖에 없는데 어떤 이론을 넣을까?'
바로 명제였다. 명제는 어디서 나왔느냐? 전기 스위치에서 나왔다.
불이 들어오는 상태 ON은 1이다. 불이 안 들어오는 상태 OFF는 0이다.
* A스위치, B스위치가 있다.

논리적 합 OR 연산자, 컴퓨터와 핸드폰에 다 들어있다.
1. A스위치가 닫히면 불이 들어온다.
2. B스위치가 닫히면 불이 들어온다.
3. A, B스위치가 닫히면 둘 다 불이 들어온다.
4. 불이 안 들어오는 상태는 둘 다 열려있을 때문이다.
스위치가 직렬로 연결되어 있는 상태
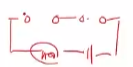
논리적 곱 AND 연산자
스위치가 하나만 닫히면 불이 안 들어온다. 왜냐면 직렬인데 중간에 끊어져있으니깐
둘 다 스위치가 ON 일 때만 전기가 흐른다.
배타적 논리합
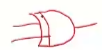
줄이 두 개인 OR연산자. 를 XOR 배타적 논리합이라고 한다.
서로 다를 때만 1이 나온다.
1 1 이면 0이나 오고, 0 0 이어도 0이 나온다.
1 0 이면 1이 나온다. 0 1 이면 1이 나온다. 이것을 이용한 게 바로 중첩 방법이다.
오버플로 해결 방법
해싱을 하다 보면 해싱버킷에 값이 넘어가는 경우가 있다.(그릇이 넘치는 경우)
그 그릇이 넘치는 것을 오버플로라고 한다. 이 밑으로는 그릇이 넘칠 때 사용하는 기법이다.
# 버킷
하나의 그릇
1. 선형 개방 주소법 (Linear Open Addressing)
- 해싱에서 충돌이 일어난 자리에서 그다음 버킷들을 차례로 검색하여 최초로 나오는 빈버켓에 해당 데이터를 저장하는 방법으로 저장할 데이터가 적을 때 유리하다.
- 포인터와 추가적 저장 공간이 필요 없다. 삽입/삭제 시 오버헤드가 적다.
2. 폐쇄 주소 방법(Closed Addressing)
- 버킷 내에 연결리스트(Linked List)를 할당하여, 버킷에 데이터를 삽입하다가 해시 충돌이 발생하면 연결리스트로 데이터들을 연결하는 방식이다.
- 연결 리스트만 사용하되 개방 주소법도가 계산식을 사용할 필요성이 낮다
- 해시 테이블이 채워질수록 Lookup 성능 저하가 발생할 수 있다.
3. 재해싱
충돌이 발생하면 새로운 해시 함수를 적용하여 새로운 홈 주소를 계산한다.
동의어(Synonym)
해싱에서 동일한 홈 주소로 인하여 충돌이 일어난 레코드들의 집합을 의미한다.
슬롯(Slot)
한 개의 레코드를 저장할 수 있는 공간으로 n개의 슬롯이 모여 하나의 버킷을 형성한다.
충돌(Collision)
- 레코드를 삽입할 때 2개의 상이한 레코드가 똑같은 버킷으로 해싱되는 것을 의미한다.
- 버킷(Bucket)이 여러 개의 슬롯(Slot)으로 구성될 때에는 충돌(Collision)이 발생하여도 오버플로우(Overflow)가 발생하지 않을 수 있다.
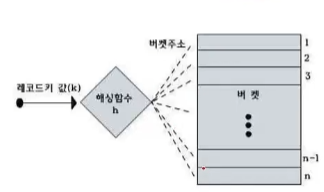
레코드 값이 오고 해싱함수에 의해서 각각 버킷주소에 할당이 된다.
만약 해당하는 버킷에 2개의 다른 레코드가 똑같이 추가가 되면 (해싱이 되면) 충돌이 발생 할 수 있다.
문제 풀이
1. 해싱에서 동일한 홈주소로 인하여 충돌이 일어난 레코드들의 집합을 의미하는 것은?
동의어
2. Linear Search의 평균 검색 횟수는?
(n+1)/2
3. 해싱 함수 중 레코드 키를 여러 부분으로 나누고, 나눈 부분의 각 숫자를 더하거나 XOR 한 값을 홈주소로 사용하는 방식은?
① 제산법
② 폴딩법
③ 기수 변환법
④ 숫자 분석법
2번
4. 해싱 테이블의 오버플로우 처리 기법이 아닌 것은?
① 개방 주소법
② 폐쇄 주소법
③ 로그 주소법
④ 재해싱
3번
5. 이진 검색 알고리즘에 대한 설명으로 틀린 것은?
① 탐색 효율이 좋고 탐색 시간이 적게 소요된다.
② 검색할 데이터가 정렬되어 있어야 한다.
③ 피보나치수열에 따라 다음에 비교할 대상을 선정하여 검색한다.
④ 비교 횟수를 거듭할 때마다 검색 대상이 되는 데이터의 수가 절반으로 줄어든다.
3번 피보나치 검색
6. 알고리즘과 관련한 설명으로 틀린 것은?
① 주어진 작업을 수행하는 컴퓨터 명령어를 순서대로 나열한 것으로 볼 수 있다.
② 검색(Searching)은 정렬이 되지 않은 데이터 혹은 정렬이 된 데이터 중에서 키값에 해당하는 데이터를 찾는 알고리즘이다.
③ 정렬(Sorting)은 흩어져 있는 데이터를 키값을 이용하여 순서대로 열거하는 알고리즘이다.
④ 선형 검색은 검색을 수행하기 전에 반드시 데이터의 집합이 정렬되어 있어야 한다.
4번 이분 검색에 대한 설명
'정처기 > 데이터베이스 구축' 카테고리의 다른 글
| 3. 데이터베이스 기초 - 39. DB, DBMS (0) | 2023.05.20 |
|---|---|
| 2. 정렬, 해싱 - 38. 인덱스, 파일편성 (0) | 2023.05.08 |
| 2. 정렬,해싱 - 36. 정렬 (0) | 2023.05.05 |
| 1. 자료구조 - 35. 비선형 구조 (0) | 2023.05.05 |
| 1. 자료구조 - 34. 자료구조 (0) | 2023.04.26 |



