
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 운영체제의 미래
- 운영체제 서비스
- 겁나 많아
- 출력
- 프로그래밍
- 패킷트레이서 이용
- 딥러닝
- 절차적 사고의 장점
- 국립과천과학관
- 장치에 할당할 수 없는 NET ID Broadcast주소
- 선택
- 레지스터
- gensim 3.7.3 설치 오류
- 운영체제 목적
- 뿌..
- 컴퓨터
- 미래 사회의 단위
- 해결 방안
- 처리
- 절차적 사고
- 소프트웨어 시대
- 앨런 튜링
- 말 인용
- 기계어
- 운영체제의 발달 과정
- 운영체제의 기능 1. 자원 관리 기능 2. 시스템 보호 3. 네트워크(통신 기능)
- 공부정리
- 소프트웨어
- 순서도
- 반복 구조 찾기
- Today
- Total
hye-_
4. 결함 성능 - 30. 성능 개선 본문
30. 성능 개선
1. 성능 측정 지표
2. 위험 감시
3. 알고리즘 설계 기법
4. 시간 복잡도
5. 순환 복잡도
1. 성능을 측정 지표
뭔가 성능을 측정할 때는 밑에 있는 것이 나온다.
1. 처리량 (Throughput)
주어진 시간에 처리할 수 있는 프로세스 처리 수
예 )
한 시간에 삽질을 천 번 할 수 있는지, 백번 할 수 있는지에 대한 처리량
2. 응답 시간 (Response Time)
데이터 입력 완료 시부터 응답 출력이 개시될 때까지의 시간
예 )
구구단 1단부터 9단까지 외워봐 했을 때 1초 만에 끝나는 애들과 그렇지 않은 애들
3. 경과 시간 (Turnaround Time)
입력한 시점부터 그 결과의 출력이 완료할 때까지 걸리는 시간
예 )
입력했을때부터 피드백되는 시간 응답시간과 비슷하다. 완료되는 시간, 작업 처리 시간이 얼마나 되는지,
4. 자원 사용률 (Resource Usage)
프로세스 처리 중 사용하는 CPU 사용량, 메모리 사용량, 네트워크 사용량
예 )
A라는 작업을 시켰을 때 자원을 얼마나 쓰는지에 대한 것이다.
유형별 성능 분석 도구
1. 성능 / 부하 / 스트레스 (Performance / Load / Stress) 점검 도구
측정 지표인 처리량, 응답 시간, 경과 시간 등을 점검하기 위해 가상의 시스템 부하나 스트레스를 통해 성능을 분석하는 도구이다.
2. 모니터링 (Monitoring) 도구
성능 모니터링, 성능 저하 원인 분석, 시스템 부하량 분석, 장애 진단, 사용자 분석, 용량 산정 등의 기능을 통하여 애플리케이션 실행 시 자원 사용량을 확인하고 분석 가능한 도구이다.
2. 위험 감시 (Risk Monitoring) ☆
위험 요소 징후들에 대하여 계속적으로 인지하는 것이다.
데이터베이스 연결 및 쿼리 실행 시 발생되는 성능 저하 원인
1. DB Lock
- 과도한 데이터 조회/업데이트/인덱스 생성 시 발생한다.
- Lock의 해제 시까지 대기하거나 처리되지 못하고 종료된다.
예 ) 면처리라는 내 은행 계좌가 있다.
그러면 누군가가 은행뱅킹앱을 이용해서 돈을 이체/인출하려고 한다. 그러면 면처리라는 계좌는 다른 애들이 접근하지 못하도록 막아줘야 된다. 왜? 동시에 작업이 일어나게 되면, 불일치성이라는 문제가 발생해 무결성을 해치게 된다.
그래서 어떤 객체를 누군가 접근했을 경우에 그 외 객체가 접근하지 못하도록 하는 것을 Locking이라고 하는데
그 Locking 값을 너무 오래 유지하는 거야
그러면 사용하는 것은 계속해서 리소스에 남아있게 된다.
2. 불필요한 DB Fetch
- 필요한 데이터보다 많은 대량의 데이터 요청이 들어올 경우 발생한다.
- 결과 세트에서 마지막 위치로 커서를 옮기는 작업이 빈번한 경우 응답 시간 저하 현상이 발생한다.
# Fetch
가지고 오다
예 ) 1학년 1반의 성적 처리를 하는데
1학년 1반부터 10반까지의 데이터를 가지고 온다. 2반부터 10반까지의 데이터는 필요 없으므로 메모리의 낭비이다.
3. 연결 누수 (Connection Leak)
DB 연결과 관련한 JDBC 객체를 사용 후 종료 하지 않을 경우 발생한다.
4. 부적절한 Connection Pool Size
커넥션 풀 크기가 너무 작거나 크게 설정한 경우 발생한다.
# Connection Pool Size
연결을 하고 중간에 데이터를 넣을 수 있는 공간을 의미한다. 연결했을 때 일종의 버퍼 역할을 하는 공간의 크기를 의미.
예 )
내가 가져올 데이터는 1Byte인데 100 megabyte를 할당하면 그러면 1 mega가 올 것이므로 99 megabyte는 쓸데없이 자원이 사용되는 것이다.
5. 기타
트랜잭션이 Commit 되지 않고 커넥션 풀에 반환되거나, 잘못 작성된 코드로 인해 불필요한 Commit가 자주 발생하는 경우 발생한다.
내부 로직으로 인한 성능 저하 원인
1. 웹 애플리케이션의 인터넷 접속 불량이나 대량의 파일로 인해 부하가 발생하는 경우이다.
2. 정상적으로 처리되지 않은 오류 처리로 인한 부하나 트랜잭션이 수행되는 동안 외부 트랜잭션(외부 호출)이 장시간 수행되거나, 타임아웃이 일어나는 경우이다.
잘못된 환경 설정이나 네트워크 문제로 인한 성능 저하 원인
환경 설정으로 인한 성능 저하
Thread Pool, Heap Memory의 크기를 너무 작게 설정하면 Heap Memory Full 현상이 발생한다.
# Thread Pool
어떤 작업을 처리할 때 프로세스보다 작은 단위인 스레드의 공간
# 힙 (Heap)
- 완전 이진트리의 일종, 우선순위 큐를 위하여 만들어진 자료구조
- 여러 개의 값들 중에서 최댓값이나 최솟값을 빠르게 찾아내도록 만들어진 자료구조
네트워크 장비로 인한 성능 저하
라우터, L4 스위치 등 네트워크 관련 장비 간 데이터 전송 실패 또는 전송 지연에 따른 데이터 손실이 발생한다.
알고리즘
주어진 과제를 해결하기 위한 방법과 절차를 의미한다.
알고리즘은 자연어, 의사코드(Pseudocode), 순서도, 프로그래밍 언어를 이용하여 표현 가능하다.
#의사코드(Pseudocode)
특정 프로그래밍 언어의 문법에 따라 쓰인 것이 아니라, 일반적인 언어로 코드를 흉내 내어 알고리즘을 써놓은 코드
예 )
가다가 90 넘으면 왼쪽으로 가다가 쭉 가다가 주유소 있으면 기름 넣고 등 일반적인 언어로 써 놓은 코드
3. 알고리즘 설계 기법 ☆
1. 분할 정복법 (Divide & Conquer)
제시된 문제를 분할이 불가할 때까지 나누고, 각 과제를 풀면서 다시 병합해 문제의 답을 얻는 Top- Down 방식이다.
사용되는 알고리즘 예)
퀵 정렬 알고리즘, 병합(합병) 정렬 알고리즘
① 분할 (Divide)
정복이 필요한 과제를 분할이 가능한 부분까지 분할하고,
② 정복 (Conquer)
①에서 분할된 하위 과제들을 모두 해결(정복)한다.
③ 결합 (Combine)
그리고 ②에서 정복된 해답을 모두 취합(결합)한다.
2. 동적 계획법 (Dynamic Programming)
주어진 문제를 해결하기 위해 부분 문제에 대한 답을 계속적으로 활용해 나가는 Bottom-UP 방식이다.
사용되는 알고리즘 예)
플로이드 알고리즘, 피보나치 수열 알고리즘
재귀호출(동적 계획법)뿐만 아니라, 분할 정복법을 통해서도 구현 가능하다.
① 부분 문제로 분리
② 가장 낮은 단계의 부분 문제 해답 계산
③ 이 부분 문제의 해답을 이용해 상위 부분 문제를 해결
단점
이전 단계의 해답을 활용하기 위해 반드시 기억할 수 있는 저장소가 필요하기 때문에 속도는 빠르지만, 공간 복잡도가 커지는 단점이 있다.
3. 탐욕법 (Greedy Method)
국소적인 관점에서 최적의 해결 방법을 구하는 기법으로 최적의 해결 방법을 구하지는 못하나 동적 계획법보다 효율적이라고 할 수 있다.
사용되는 알고리즘 예)
크루스칼 알고리즘, 다익스트라 알고리즘
4. 퇴각 검색법 (Back tracking)
어떤 문제의 최적해를 구하기 위해 모든 가능성을 찾아가는 방법이다.
동적 계획법과 같이 기억할 저장소를 필요로 한다.
N-Queen 문제 해결 시에 응용된다.
N*N 체스판에 N개의 퀸을 서로 공격할 수 없게 배치하는 경우의 수를 출력하는 문제
5. 분기 한정법 (Branch & Bound)
정해진 범위(Bound)를 벗어나는 값들은 가지치기 (Branch) 해가며 결과값을 추적해 나가는 방식이다.
사용되는 알고리즘 예 )
최적 우선 탐색 (Best First Search) 알고리즘, A*알고리즘
6. 근사 해법 (Approximation Algorithm)
복잡도가 매우 높은 문제에 대해 가장 근사치와 값을 구하는 기법이다.
시간 복잡도, 공간복잡도, 정밀도를 척도로 평가한다.
사용되는 알고리즘 예)
근사 알고리즘
NP-Hard 문제를 해결하기 위해, 주어진 시간에 최적해에 가장 가까운 답을 찾는 결정성 알고리즘을 구현하는 기법이다.
다항식 시간에 풀기 어렵다고 판단되는 문제
4. 시간 복잡도에 따른 알고리즘
시간 복잡도는 알고리즘이 문제를 해결하기 위한 시간(연산)의 횟수를 말한다.
시간 복잡도를 고려하는 것은 최적화를 위해 필요하다.
알고리즘의 소요 시간에 대한 정확한 평가는 어려워 자료의 수 N이 증가할 때 시간이(Time Complexity; 복합성) 증가하는 대략적인 패턴을 의미한다.
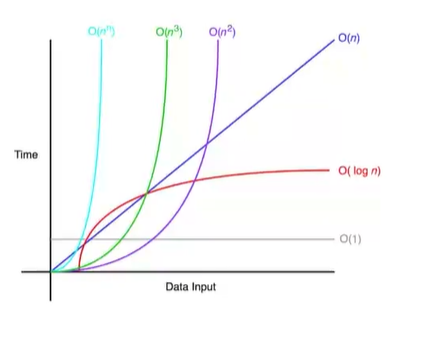
시간 복잡도 Big-o 표기법 ☆
| o (1) | 상수 시간의 복잡도를 의미하며 입력값 n이 주어졌을 때, 문제를 해결하는데 오직 한 단계만 거친다 (해시 함수) |
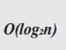 |
로그 시간의 복잡도를 의미하며 입력값 n이 주어졌을 때, 문제를 해결하는데 필요한 단계들이 연산마다 특정 요인에 의해 줄어든다 (이진 탐색) |
 |
선형 로그 시간의 복잡도를 의미하며 문제 해결을 위한 단계수는 nlog2n 번의 수행 시간을 갖는다 (퀵 정렬, 병합(합병) 정렬) - 힙 정렬(Heap Sort)의 평균 수행시간도 해당 표기법으로 표시한다. |
 |
선형 시간의 복잡도를 의미하며 문제를 해결하기 위한 단계의수와 입력값 n이 1:1 관계이다 (순차 탐색) |
 |
제곱 시간의 복잡도를 의미하며 문제를 해결하기 위한 단계의 수는 입력값 n의 제곱근이다(거품 정렬, 삽입 정렬, 선택 정렬) |
 |
지수 시간의 복잡도를 의미하며 문제를 해결하기 위한 단계의 수는 주어진 상수값 C의 n 제곱이다. |
log n
- 우리가 인터넷 검색을 하면 밑수는 표시 안 한다. 밑수 표시 안 하는 값을 많이 볼 수 있다.
시험 문제는 밑수를 준다. 그래프의 크기 변경에는 차이가 없다.
그래프의 모양은 이렇다.
- 데이터 인풋에서 가장 많이 볼 수 있다.
퀵 정렬, 병합(합병) 정렬
- 일반적으로 어떤 값을 주어졌을 때 시간이 좀 많이 소요되다가 어느 정도 데이터가 안정화되면 그 값으로 유지가 되는 형태이다.
- 초기에는 급격하게 시간이 늘어나지만 데이터가 나중에 많아졌을 때 효과적이다.
거품정렬 삽입 정렬, 선택 정렬
- 내가 주어진 데이터 값이 처음에는 입력되는 값하고 시간하고 비슴듬히 올라가다가 데이터가 갑자기 많아지면
갑자기 시간이 많아지는 방식이다.
- 데이터가 적을 때는 효과적인데 데이터가 많을 때는 사용하면 안 된다.
정렬을 할 때
내가 가지고 있는 데이터에 따라서 어떤 방식을 써야 될지 판단해야 된다.
n
입력되는 값의 크기(개수)를 의미한다.
5. 순환 복잡도
프로그램의 이해 난이도는 제어 흐름 난이도의 복잡도에 따라 결정되며, 복잡도를 싸이클로메틱 개수에 의해서 산정하는 방법이다.
- 싸이클로메틱의 개수와 원시 프로그램 오류의 개수는 밀접한 관계가 있다.
- 최대 10을 넘지 않도록 하며 넘으면 이를 분해하도록 한다.
싸이클로메틱 은 순환복잡도를 의미한다.
Mccabe Cyclomatic Complexity
복잡도 계산 방식
복잡도 = 화살표 수 - 노드 수 + 2
제어 흐름그래프를 통해 파악
복잡도 = 영역 수 (폐 구간 ) + 1 (제어 흐름 그래프를 통해 파악)
복잡도 = 의사 결정수 + 조건 수 + 1 (프로그램 코드상에서 파악, 제어 흐름도를 그리기 어려운 경우 활용한다.)
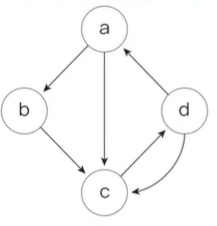
복잡도 계산 방식 예제 ☆
제어 흐름 그래프가 다음과 같을 때 McCabe의 Cyclomatic 수는 얼마인가? 4
순환 복잡도
V(G) = E - N + 2
= 6 - 4 + 2
= 4
E
화살표 수, N은 노두 수(점)
문제 풀이
1. 알고리즘 설계 기법 중 제시된 문제를 분할이 불가할 때까지 나누고, 각 과제를 풀면서 다시 병합해 문제의 답을 얻는 Top-Down 방식은?
분할 정복 법
2. 특정 프로그래밍 언어의 문법에 따라 쓰인 것이 아니라, 일반적인 언어로 코드를 흉내 내어 알고리즘을 써놓은 코드는 무엇인가?
의사 코드
3. 알고리즘 설계 기법으로 거리가 먼 것은?
① Divide and Conquer
② Greedy
③ Static Block
④ Backtracking
3번
1. 제어 흐름 그래프가 다음과 같을 때 McCabe의 Cyclomatic 개수는 얼마인가?
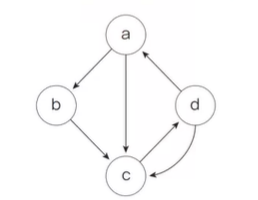
6- 4 + 2 = 4
4개
2. 정렬된 N개의 데이터를 처리하는데 밑그림의 시간이 소요되는 정렬 알고리즘?

① 합병정렬
② 버블정렬
③ 선택정렬
④ 삽입정렬
1번
3. 힙 정렬 (Heap Sort)에 대한 설명으로 틀린 것은?
① 정렬할 입력 레코드들로 힙을 구성하고 가장 큰 키 값을 갖는 루트 노드를 제거하는 과정을 반복하여 정렬하는 기법이다
② 평균 수행 시간은 (nlog₂n)이다.
③ 완전이진트리(complete binary tree)로 입력자료의 레코드를 구성한다.
④ 최악의 수행시간은 0(2n₄)이다.
4번
힙 정렬은 최악, 평균, 최적 시간이 모두 다 같다.
4. 알고리즘 시간복잡도 0(1)이 의미하는 것은?
① 컴퓨터 처리가 불가
② 알고리즘 입력 데이터 수가 한 개
③ 알고리즘 수행시간이 입력 데이터 수와 관계없이 일정
④ 알고리즘 길이가 입력 데이터보다 작음
3번
0(1)은 일정하다는 의미이다.
'정처기 > 소프트웨어 구현' 카테고리의 다른 글
| 5. 인터페이스 구현 - 32. 인터페이스 구현 (0) | 2023.04.25 |
|---|---|
| 4. 결함 성능 - 31. 소스코드 최적화 (0) | 2023.04.25 |
| 4. 결함 성능 - 29. 결함 관리 (0) | 2023.04.24 |
| 3. SW 테스트 - 28. 통합 테스트 (1) | 2023.04.24 |
| 3. SW 테스트 - 27. 테스트 커버리지 (0) | 2023.04.24 |



